伯克利提出轻量级语音合成声码器SqueezeWave大幅降低计算量
伯克利提出轻量级语音合成声码器SqueezeWave大幅降低计算量今天为大家介绍一项来自UC Berkeley的新工作:SqueezeAI family里最新的一员——用于移动端语
今天为大家介绍一项来自UC Berkeley的新工作:SqueezeAI family里最新的一员——用于移动端语音合成的流模型SqueezeWave。作者用了一些很简单的方法,设计了一个非常精简得流模型。和此前Nvidia 的WaveGlow相比,相似的语音效果下,他们的模型所需算力比原有模型小214倍,在树莓派上都能做到实时生成的速度。

自动语音合成对于众多智能应用十分重要,其中声学特征转换为音频输出的声码器在语音合成过程中具有十分重要的作用。虽然WaveGlow可以实现并行化的语音合成,但其庞大的计算量使得本地和边缘设备无法承受,基于云计算的语音合成使得网络延时和用户隐私问题无法有效解决。为了解决语音合成中计算效率的问题,来自加州大学伯克利分校的研究人员提出了一种超轻量级的声码器模型SqueezeWave,通过对WaveGlow的结构和计算方法进行优化大幅提升了模型计算效率,相较于WaveGlow减小了61-214倍的计算量,在众多边缘设备上——甚至是树莓派上——都能有效部署实现高效的实时语音合成。
TTS从云端向边缘
从车载地图应用到语音助手,众多设备都开始采用了丰富的语音交互技术来处理各种任务。但想要得到高质量的文本到语音转换,需要复杂的机器学习模型和庞大的云计算资源支撑。但随着硬件的发展,边缘设备的计算能力大幅提升使得语音合成模型在本地运行成为可能。其次消费者对于隐私的担忧与日俱增,在移动端运行机器学习模型消除用户数据向云端泄漏的威胁。此外随着消费者对于语音助手的依赖逐渐加深,对于用户体验的关注也逐渐增加。为了提供低延时的语音服务,降低网络连接质量带来的影响,本地运行的语音合成模型比云端模型更有优势。
典型的现代语音合成模型主要包含两个部分:合成器和声码器。其中合成器用于从文字输入生成声学特征,而后利用声码器从声学特征生成波形输出。现存的高质量语音合成器都需要消耗十分可观的计算资源,SqueezeWave的主要目的在于提升合成器的效率。例如WaveNet及其变体基于自回归的方法,意味着每一个生成的样本都依赖于先前的样本,这种串行的处理方式阻碍了硬件的并行加速;而基于流的WaveGlow可以在每一次前传中生成许多样本,虽然这一方法具有并行优势但却需要消耗十分巨大的计算量。例如生成1s22kHz的语音需要消耗229G MACs的计算量,远远超过了移动端处理器所能承受的范围。尽管WaveFlow可以在最新的V100显卡上达到超过实时的性能,但却不适合在边缘设备部署。
在这篇论文中研究人员提出了一种轻量级的基于流的声码器SqueezeWave用于边缘设备的语音合成。研究人员重新设计了WaveGlow的架构,通过重整音频张量、采用深度可分离卷积以及相关优化使其比WaveGlow少消耗61-214倍的计算量,可在笔记本端实现每秒123-303K样本的生成,在树莓派上3B+上也能实现15.6K的实时水平。
重新审视WaveGlow的计算复杂度
与直接进行卷积操作不同,WaveGlow首先将邻近的样本聚类构建多通道的输入,其中L为时域维度的长度,Cg为每个时间步上的聚类组合的样本数量。波形中的样本总数量为.波形随后被一系列双边映射进行转换,其中每一个都会利用的输入得到输出。在每个双边映射中,输入信号首先被可逆的逐点卷积处理,而后将结果沿通道拆分为和。其中被用于计算仿射耦合系数.其中将被应用于的后续计算。而则为类似wavenet的函数,为编码音频的梅尔谱Lm为梅尔谱的时间长度,Cm为频率分量的数目。随后仿射变换层将通过下式计算:,其中代表逐元素相乘。最终将在通道方向上组合得到最后的输出。
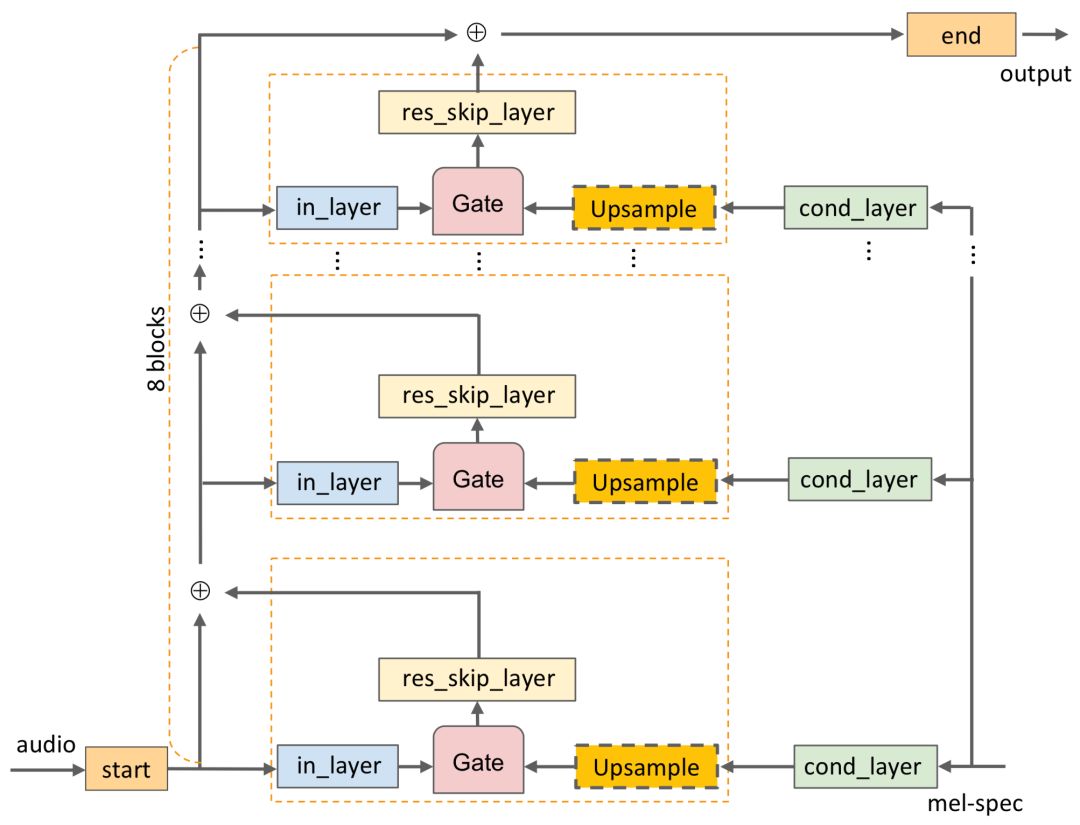
WaveGlow最主要的计算量来自于WN函数,其计算流程上图所示。输入首先通过逐点卷积进行处理(图中start),卷积使得的通道数从增加到非常大的数目,在WaveGlow中start的输出维度为256维。随后核为3的一维膨胀卷积将继续对上述结果进行处理(图中in_layer所示)同时梅尔谱也被馈入到网络中。由于梅尔谱的时域长度远小于波形长度,所以需要对其进行上采样来进行维度匹配。而后in_layer和cond_layer输出按照WaveNet的方式通过门函数进行合并,随后传输到res_skip_layer。其输出长度为L=2000,通道数为512.随后将按照通道拆分为两部分。这一结构将重复八次,并在最后的res_skip_layer输出与end进行逐点卷积,计算出转换因子
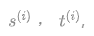
并将通道从512压缩到8。在WaveGlow的源码中,每秒的计算量为229G MACs,其中in_layer占据了47%,cond_layer占据了39%, res_skip_layer则为14%。这对这样的情况,研究人员将对原始的网络结构进行改进以减少计算量提高计算效率。
SqueezeWave的改进措施
通过对WaveGlow的分析发现最主要的计算量来自于输入音频波形的形状(长度)。WaveGlow的输出维度为(L=2000,Cg = 8)这会从三个方面带来非常高的计算复杂度:WaveGlow是一维卷积,其计算复杂度随L线性增长;为了提高梅尔谱的时域分辨率需要对其进行上采样,由于上采样是由现有样本简单插值而成的意味着in_layer中其中绝大部分计算是没有必要的;在WN函数中,8通道的输入被映射到了256到512维中间维度,虽然增加了模型容量但是在输出时又被压缩为8通道,中间维度的信息将会不可避免的丢失。
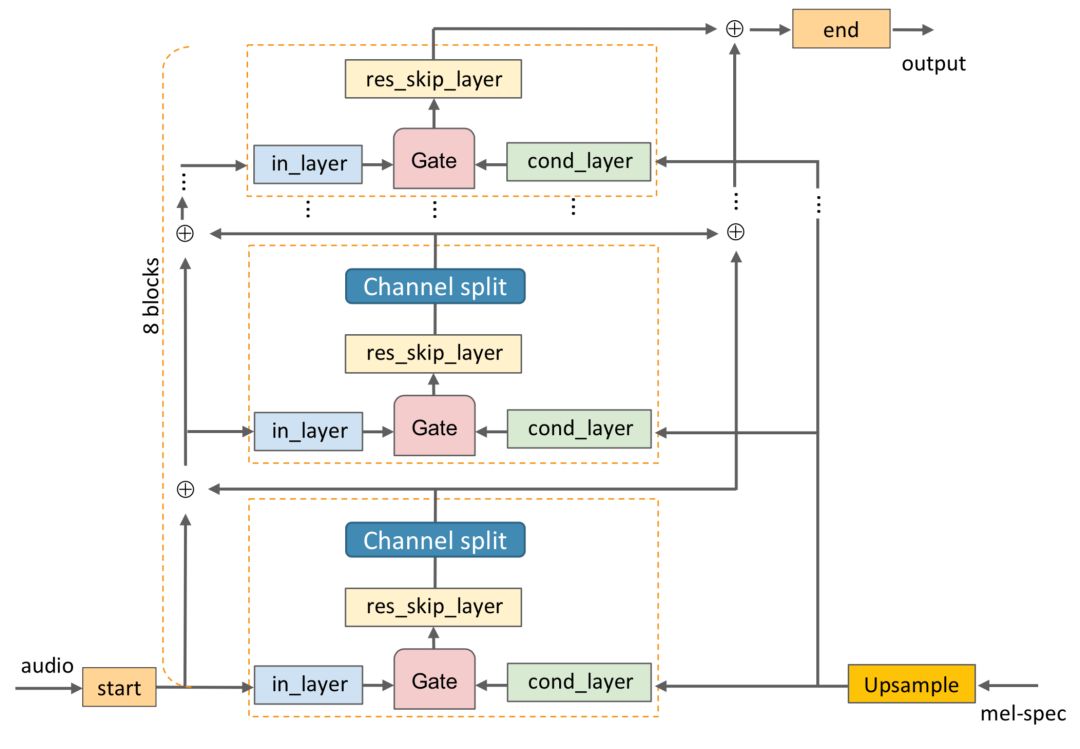
为了改进这些计算复杂的细节,研究人员将输入音频变形为较小的时域长度和较多的通道上来,同时保持WN函数中的通道尺寸。下面是两种改进的细节。当L=64时,时域长度与梅尔谱相同无需上采样,而L=128时,梅尔谱仅需要进行最邻近采样,这样进一步减少了cond_layer的计算开销。fig2深度可分离卷积减小计算量。
此外,研究人员还利用深度可分离卷积代替了in_layer中的一维卷积,用于处理1D音频信号。一维卷积将输入转换为,其中卷积核的尺寸为,计算量为MACs.利用深度可分离卷积可以将计算量减小为:当K=3,Cout = 512时候,这种方法可以减小近三倍的计算量。
除此之外,由于时域长度减小不再需要利用膨胀卷积增加感受野,所以都用常规卷积进行代替更加适合硬件计算;将res_skip_layer的两支输出分支合并,减小了最终的输出通道数目。在下图中可以看到SqueezeWave的改进:
实验结果
为了验证模型的性能,研究人员将本文提出的SqueezeWave(SW)与WaveGlow和基准进行了比较,下表中SW-128L代表L=128的模型:
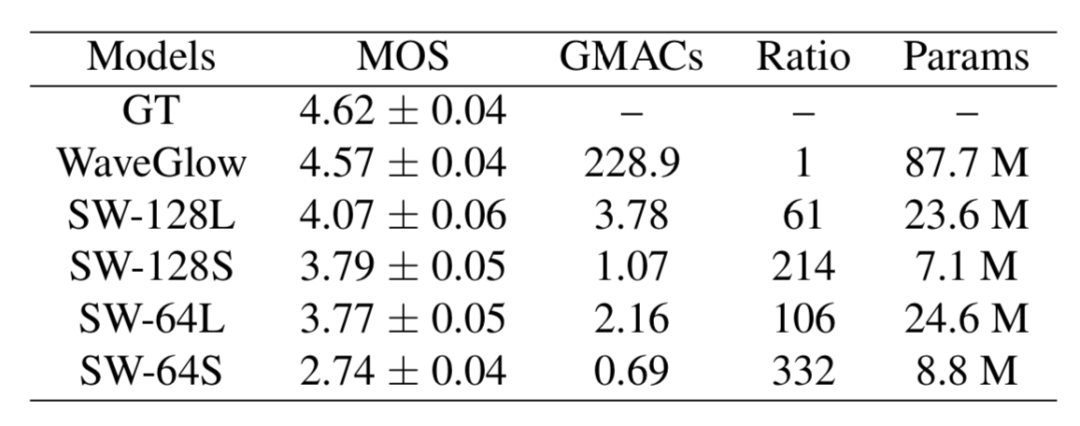
可以看到SW系列模型的计算量相较于WaveGlow大幅下降,而性能却能保持较高的水平。

为了验证在边缘设备的性能,下表还比较了在MacbookPro和树莓派上的结果,可以看到甚至在树莓派上都可以达到5.2k-21k/s的样本生成速度。其中SW128S以及能够生成实时并且高质量的音频结果了。
上一篇:拓斯达斩获立讯精密6.5亿大订单
-
点云上采样新方法:港城大提出几何参数域模型实现高效点云加密2020-03-23
-
高效共享GPU!浪潮AIStation突破企业AI计算资源极限2020-03-20
-
以色列量子计算初创公司Quantum Machines获得A轮1750万美元融资2020-03-20
-
计算机界“诺贝尔奖”公布:2019年图灵奖被授予两位皮克斯动画工作室元老2020-03-20
-
拥抱5G发展机遇,从边缘计算上车2020-03-14
-
DeepTalk深言堂 | 清华刘永进:多模态情感计算2020-03-10
-
模拟内存计算如何解决边缘AI推理的功耗挑战2020-03-06
-
AT&T与谷歌云达成合作 共同开发5G边缘计算解决方案2020-03-06
-
3D打印新操作 智能算法助你随心设计专属人像模型2020-03-04
-
3D打印新操作 | 智能算法助你随心设计专属人像模型2020-03-04
-
百度飞桨助力连心医疗业内首次开源肺炎CT影像分析AI模型,支援各界共同抗疫2020-02-29
-
人工智能如何打造微软的普适计算愿景2020-02-28
-
RTI公司加入自动驾驶汽车计算联盟,支持高端自动驾驶汽车架构2020-02-28
-
RTI公司加入自动驾驶汽车计算联盟(AVCC),支持高端自动驾驶汽车架构2020-02-28
-
如何科学估算新冠肺炎病死率?森亿智能大数据模型揭示其变化规律2020-02-26