中科院计算所副研究员冯洋:神经机器翻译的训练改进和解码提速
中科院计算所副研究员冯洋:神经机器翻译的训练改进和解码提速当前机器翻译模型通常采用自注意力机制进行编码,训练时直接将Ground Truth词语用作上文,并行生成所有的目标词语,极
当前机器翻译模型通常采用自注意力机制进行编码,训练时直接将Ground Truth词语用作上文,并行生成所有的目标词语,极大的提升了训练速度。
但测试的时候却面临以下难题:首先,模型得不到Ground Truth,从而只能用自己生成的词作为上文,使得训练和测试的分布不一致,影响了翻译质量;其次,由于每个目标词语的生成依赖于其之前生成的词,所以目标词语只能顺序生成,不能并行,从而影响了解码速度。本次分享将针对以上问题,介绍他们的解决方法。
具体分享内容如下:
1. 改进训练和测试的分布不一致问题:
采用计划采样的方法 (ACL 2019 best paper)
采用可导的序列级损失函数进行贪心搜索解码
2. 解码速度提升:
基于Cube Pruning解码算法
融入序列信息的非自回归翻译模型
背景
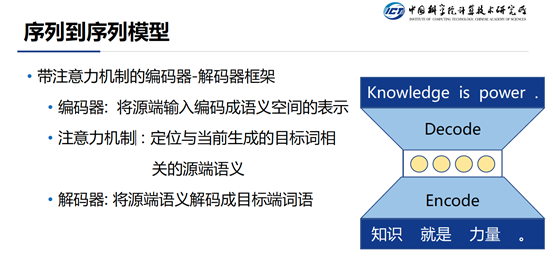
当前,自然语言处理方向的生成任务主要包括:机器翻译,人机对话,文章写作,文章摘要等等。目前这些问题主要是通过序列到序列模型来解决的。序列到序列模型的主要架构是一个带有注意力机制的编码器-解码器架构。这个架构基于一个重要的假设:即“源端的输入和目的端的输出之间是可以找到一个共同的语义空间。编码器的任务就是对输入进行各种变换,映射到共同语义空间上的一个点。解码器的任务是对共同语义空间的这个点进行一些反操作,将其映射到目标端空间,从而生成相应的词语。考虑到在每一步进行翻译的时候不需要关注所有的源端输入,而是仅仅关注一部分,注意力机制主要目的就是将当前步需要关注的部分找出来。
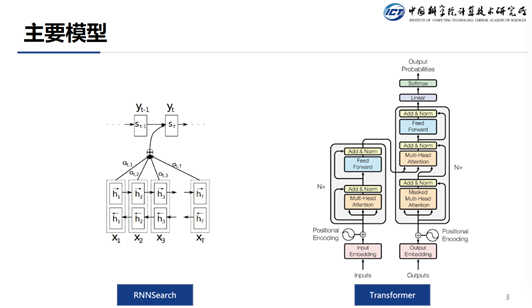
目前主流的序列到序列模型主要包括两种: 一个是RNNSearch,一个是Transformer。
RNNSearch通过RNN来将源端的输入编码成一个表示,通常源端采用的是双向RNN,这样对于每一个源端Token的编码表示都能考虑到其上下文信息。在目标端同样是使用一个RNN,它可以将翻译的历史信息给串起来,这样在当前步翻译的时候就能考虑到上文的信息。
Google在2017年提出了Transformer结构,该结构经过无数人的验证,发现非常好用,所以Transformer就成为了当前主流的序列到序列模型。Transformer主要的机制是:在生成源端表示的时候并没有使用RNN,而是使用自注意力机制来生成每一个Token的表示。这样做的好处是,在训练的时候可以并行,因为每个词都可以并行的和其它词计算attention ( RNN则只能串行 )。同样在解码端的时候,也是使用的自注意力机制。
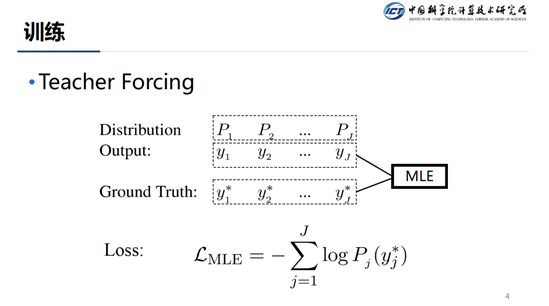
这种模型在训练的时候都是采用的TeacherForcing形式。模型在解码当前步的时候,通常会有三个输入:解码器当前的状态,attention和上一步解码的结果。在训练的过程中,我们通常使用上一步的真实输出而非模型输出作为当前步解码的结果,这就是所谓的Teacher Forcing。

在Inference的时候通常采用Beam-Search +顺序生成的方式,在每一步都保存Top-K个最优结果。

在介绍了训练和推断之后,我们来看一下目前面临的问题,因为在训练的时候我们使用Teacher Forcing的方式,但是我们在推断的时候并不知道上一步的GroundTruth是什么,所以,我们只能将上一步预测的结果来近似为Ground Truth。这样,训练和推断在生成分布的条件上就产生了差异(Ground Truth vs Predicted),这个问题被称作为 Exposure Bias。

在训练的时候,我们还存在另一个问题。训练的时候由于我们使用的交叉熵损失函数,该损失函数只对Ground Truth友好,对于非Ground Truth的结果一视同仁。但是对于翻译任务来说,并不是只有一种翻译方式,从slides中可以看到,Output1和Ground Truth表示的是同一个意思,但是Output2和Ground Truth表示的含义就是不同了,但是在训练的时候,交叉熵损失函数会将Output1和Output2一视同仁,这样是不合理的。
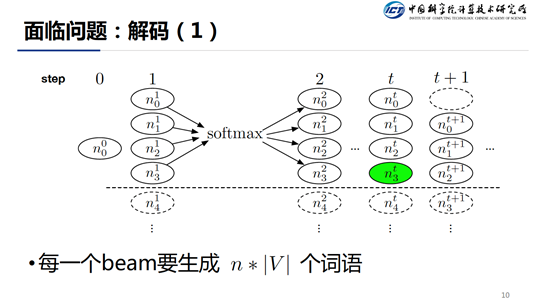
在推断阶段解码的时候同样存在两个问题,在每一个解码step我们都要执行n各预测,每个预测都要得到整个词表的一个分布,所以在每一个step都要生成n*|V|个词语。而且每个时间步还必须串行,这大大影响了解码速度。
3 4 5 首页 下一页 上一页 尾页-
完成B+轮融资,服务多家世界500强,解码灵动科技企业服务2020-04-02
-
专访丨完成B+轮融资,服务多家世界500强,解码灵动科技企业服务2020-04-02
-
50倍序列数据分析速度提升,NVIDIA为COVID-19研究人员免费提供Parabricks2020-03-27
-
新算法增强无人车在仿真环境中的训练效果2020-03-11
-
新算法可以增强无人车在仿真环境中的训练效果2020-03-11
-
解码京东Q4财报,刘强东向技术与服务转型成效显著2020-03-10
-
深兰科学院基础研究厚积薄发,“长序列比对算法‘助攻战’疫”2020-03-10
-
深兰科学院基础研究厚积薄发,“长序列比对算法”助攻战“疫”2020-03-10
-
华为搜索海外测试上线;三部门发布人工智能训练师等16个新职业2020-03-03
-
“XR”与人工智能技术在美军“飞行员未来训练”计划中发挥作用2020-02-29
-
Adaptive Biotech: 用基因测序解码自适应免疫系统,受微软、罗氏青睐2020-02-24
-
《中国科学:生命科学》英文版:武汉肺炎病毒基因序列与SARS高度相似2020-01-22
-
AI训练师“正名”,没有考试,企业将成为技能等级认定主体2020-01-06
-
解码苏州金龙的2019:发力一带一路 海外市场高质量增长2019-12-30
-
解码百度Apollo智能车联开放平台 受益的不止车企2019-12-23