自动驾驶相机-激光雷达深度融合综述及展望
自动驾驶相机-激光雷达深度融合综述及展望本文是加拿大滑铁卢大学CogDrive实验室对当前最新的基于深度学习的相机-激光雷达融合(camera-LiDAR Fusion)方法的综述
本文是加拿大滑铁卢大学CogDrive实验室对当前最新的基于深度学习的相机-激光雷达融合(camera-LiDAR Fusion)方法的综述。
本篇综述评价了基于相机-激光雷达融合的深度补全,对象检测,语义分割和跟踪方向的最新论文,并根据其融合层级进行组织叙述并对比。最后讨论了当前学术研究与实际应用之间的差距和被忽视的问题。基于这些观察,我们提出了自己的见解及可能的研究方向。

01.背景
基于单目视觉的感知系统以低成本实现了令人满意的性能,但却无法提供可靠的3D几何信息。双目相机可以提供3D几何信息,但计算成本高,且无法在高遮挡和无纹理的环境中可靠的工作。此外,基于视觉的感知系统在光照条件复杂的情况下鲁棒性较低,这限制了其全天候能力。而激光雷达不受光照条件影响,且能提供高精度的3D几何信息。但其分辨率和刷新率低,且成本高昂。
相机-激光雷达融合感知,就是为了提高性能与可靠性并降低成本。但这并非易事,首先,相机通过将真实世界投影到相机平面来记录信息,而点云则将几何信息以原始坐标的形式存储。此外,就数据结构和类型而言,点云是不规则,无序和连续的,而图像是规则,有序和离散的。这导致了图像和点云处理算法方面的巨大差异。在图1中,我们比较了点云和图像的特性。

图1.点与数据和图像数据的比较
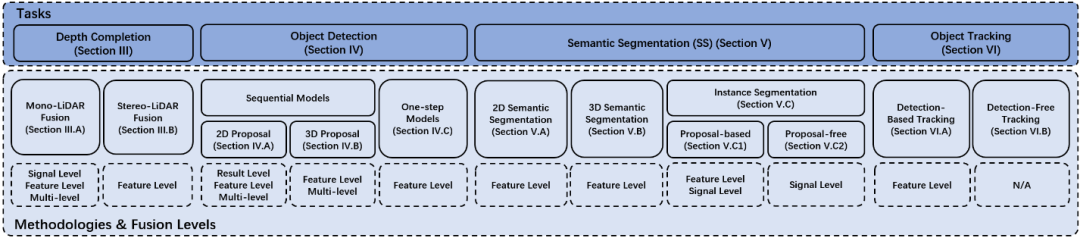
图2. 论文总体结
02.趋势,挑战和未来研究方向
无人驾驶汽车中的感知模块负责获取和理解其周围的场景,其输出直接影响着下游模块(例如规划,决策和定位)。因此,感知的性能和可靠性是整个无人驾驶系统的关键。通过摄像头-激光雷达融合感知来加强其性能和可靠性,改善无人驾驶车辆在复杂的场景下的感知(例如城市道路,极端天气情况等)。因此在本节中,我们总结总体趋势,并讨论这方面的挑战和潜在影响因素。如表IV所示,我们将讨论如何改善融合方法的性能和鲁棒性,以及与工程实践相关的其他重要课题。如下是我们总结的图像和点云融合的趋势:
2D到3D:随着3D特征提取方法的发展,在3D空间中定位,跟踪和分割对象已成为研究的热点。
单任务到多任务:一些近期的研究[64] [80]结合了多个互补任务,例如对象检测,语义分割和深度完成,以实现更好的整体性能并降低计算成本。
信号级到多级融合:早期的研究经常利用信号级融合,将3D几何图形转换到图像平面以利用现成的图像处理模型,而最近的模型则尝试在多级融合图像和点云(例如早期融合,晚期融合)并利用时间上下文。

表I. 当前的挑战
A.与性能相关的开放研究问题
1)融合数据的(Feature/Signal Representation)特征/信号表示形式:
融合数据的Feature/Signal Representation是设计任何数据融合算法的基础。当前的特征/信号表示形式包括:
a) 在RGB图像上的附加深度信息通道(RGB-D)。此方法由于可以通过现成的图像处理模型进行处理,因此早期的信号级融合常使用这种表达形式。但是,其结果也限制于2D图像平面,这使其不适用于自动驾驶。
b) 在点云上的附加RGB通道。此方法可以通过将点投影到像平面进行像素点关联来实现。但是,高分辨率图像和低分辨率点云之间的分辨率不匹配会影响此方式的效率。
c) 将图像和点云特征/信号均转换为(intermediate data representation)其他的数据表示形式。当前的intermediate data representation包括:(voxelized point cloud)体素化点云[75],(lattice)晶格[88]。未来的研究可以探索其他新颖的中间数据结构,例如(graph)图,(tree)树等,从而提高性能。
2)(Encoding Geometric Constraint)加入几何约束:
与其他三维数据源(如来自立体相机或结构光的RGBD数据)相比,LiDAR有更长的有效探测范围和更高的精度,可提供详细而准确的3D几何形状。几何约束已成为图像和点云融合流程中的常识,其提供了额外的信息来引导深度学习网络实现更好的性能。将点云以RGBD图像的形式投影到图像平面似乎是最自然的解决方法,但是点云的稀疏性会产生空洞。深度补全和点云上采样可以在某种程度上解决该问题。除此之外利用单眼图像预测深度信息以及在连续帧之间引入自我监督学习,也有望缓解这个问题。但是,如何将这种几何信息加入到融合流程中仍是当前研究实践中尚需解决的问题。
3)(Encoding Temporal Context)加入时间上下文:
还有一些工程问题阻碍了无人驾驶汽车的实际部署,例如LiDAR与摄像头之间的时间不同步,LiDAR的低刷新率导致车速高时的点云变形,LiDAR传感器测距误差。这些问题将导致图像与点云,点云与实际环境之间的不匹配。根据深度补全方面的经验,可以采用连续帧之间的时间上下文来改善姿态估计,从而改善特征融合的性能并使得下游的的header网络受益。在自动驾驶中,准确估算周围车辆的运动状态至关重要,时间上下文有助于获得更平滑,更稳定的结果。此外,时间上下文可能有益于在线自校准。因此,应对加入时间上下文进行更多的研究。
首页 下一页 上一页 尾页-
DBFace,被《机器之心》扒出来的轻量级高精度人脸检测模型2020-04-15
-
天有不测风云, 提前8小时预测! 谷歌提出基于深度学习的降水预测模型MetNet2020-04-10
-
抗击疫情!武汉大学提出口罩人脸识别数据集和模型, 95%精度不在话下2020-04-09
-
康奈尔大学研究员提出利用归一化信息, 提取图像特征中结构性信息的新方法2020-04-09
-
妈咪知道深圳儿科诊所业务接入企鹅杏仁,企鹅杏仁“城市模型”战略步伐加快2020-04-08
-
华为发布计算视觉计划,持续挑战视觉模型等三大问题2020-03-28
-
又快又好的智能主体: 谷歌提出基于世界模型的的大规模强化学习方法Dreamer2020-03-28
-
谷歌提出基于世界模型的的大规模强化学习方法Dreamer2020-03-26
-
点云上采样新方法:港城大提出几何参数域模型实现高效点云加密2020-03-23
-
增强智能与人工智能趋向融合,人机协同新时代正在到来2020-03-20
-
从形成与解读,一文为您剖析医疗图像处理2020-03-11
-
国家发改委:促进物联网、5G等智能化设施与物流深度融合2020-03-06
-
5G网络“大脑”如何高效运转?融合信令方案不可少2020-03-06
-
3D打印新操作 智能算法助你随心设计专属人像模型2020-03-04
-
3D打印新操作 | 智能算法助你随心设计专属人像模型2020-03-04