Flink未来将与 Pulsar集成提供大规模的弹性数据处理
Flink未来将与 Pulsar集成提供大规模的弹性数据处理问题导读1.什么是Pulsar?2.Pulsar都有哪些概念?3.Pulsar有什么特点?4.Flink未来如何与Pul
问题导读
1.什么是Pulsar?
2.Pulsar都有哪些概念?
3.Pulsar有什么特点?
4.Flink未来如何与Pulsar整合?
Apache Flink和Apache Pulsar的开源数据技术框架可以以不同的方式集成,以提供大规模的弹性数据处理。在这篇文章中,我将简要介绍Pulsar及其与其他消息传递系统的差异化元素,并描述Pulsar和Flink可以协同工作的方式,为大规模弹性数据处理提供无缝的开发人员体验。
Pulsar简介
Apache Pulsar是一个开源的分布式pub-sub消息系统,由Apache Software Foundation管理。Pulsar是一种用于服务器到服务器消息传递的多租户,高性能解决方案,包括多个功能,例如Pulsar实例中对多个集群的本地支持,跨集群的消息的无缝geo-replication,非常低的发布和端到端 - 延迟,超过一百万个主题的无缝可扩展性,以及由Apache BookKeeper等提供的持久消息存储保证消息传递。现在让我们讨论Pulsar和其它pub-sub消息传递框架之间的主要区别:
第一个差异化因素源于这样一个事实:虽然Pulsar提供了灵活的pub-sub消息传递系统,但它也有持久的日志存储支持 - 因此在一个框架下结合了消息传递和存储。由于采用了分层架构,Pulsar提供即时故障恢复,独立可扩展性和无平衡的集群扩展。
Pulsar的架构遵循与其他pub-sub系统类似的模式,因为框架在主题中被组织为主要数据实体,生产者向主体发送数据,消费者从主题(topic)接收数据,如下图所示。
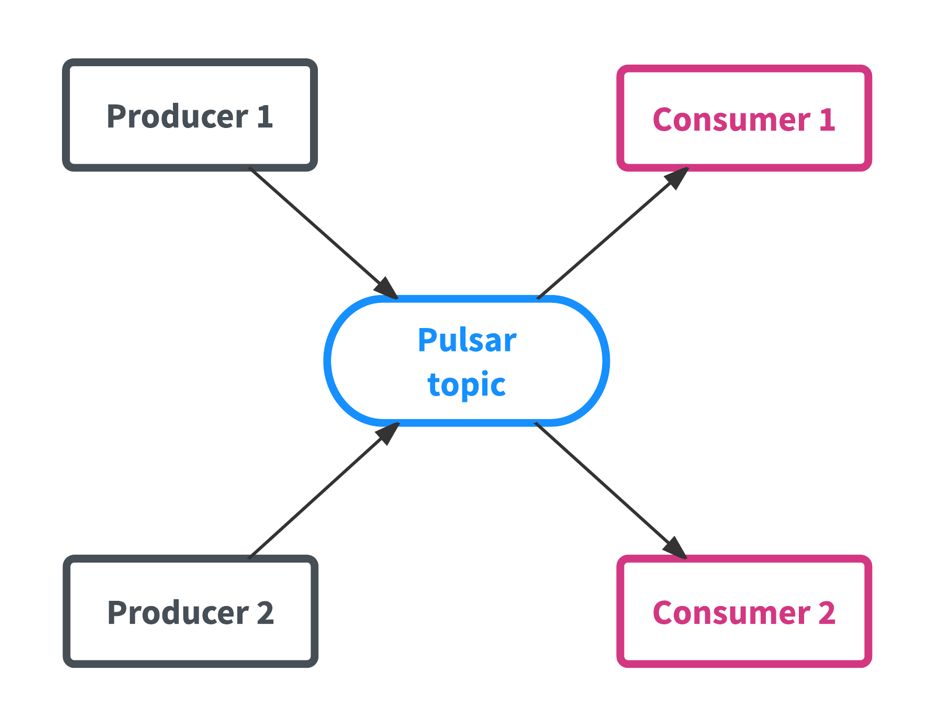
Topic是Pulsar的核心概念,表示一个“channel”,Producer可以写入数据,Consumer从中消费数据(Kafka、RocketMQ都是这样)。
Topic名称的URL类似如下的结构:
{persistent|non-persistent}://tenant/namespace/topic
persistent|non-persistent表示数据是否持久化(Pulsar支持消息持久化和非持久化两种模式)
Tenant为租户
Namespace一般聚合一系列相关的Topic,一个租户下可以有多个Namespace
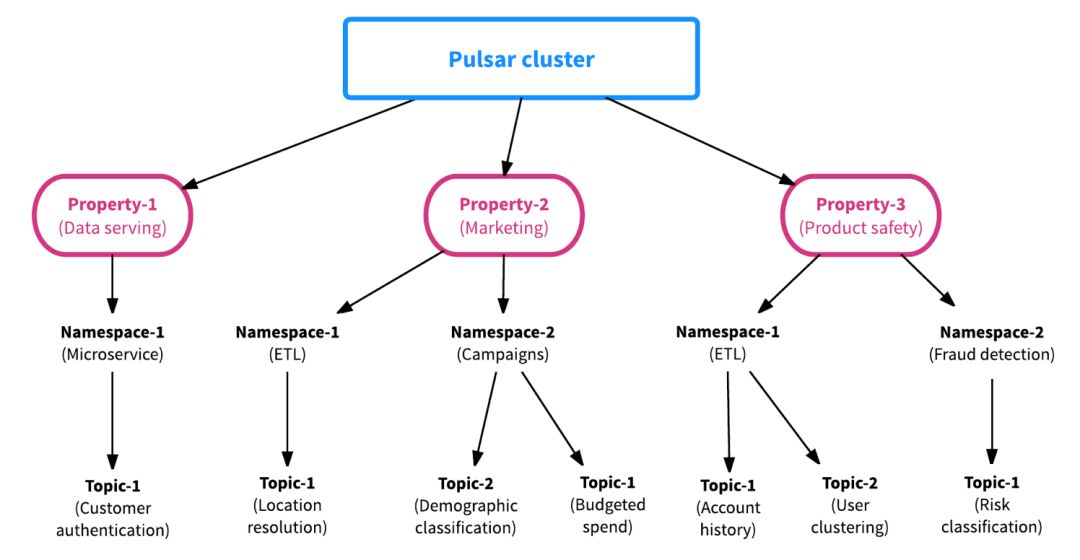
Pulsar的第二个区别是该框架是从一开始就考虑多租户而构建的。这意味着每个Pulsar主题都有一个分层的管理结构,使得资源的分配以及团队之间的资源管理和协调变得高效和容易。借助Pulsar的多租户结构,数据平台维护人员可以在没有摩擦的情况下加入新团队,因为Pulsar在属性(租户),命名空间或主题级别提供资源隔离,同时数据可以在集群中共享以便于协作和 协调。
下图中Property即为租户,每个租户下可以有多个Namespace,每个Namespace下有多个Topic。
Namespace是Pulsar中的操作单元,包括Topic是配置在Namespace级别的,包括多地域复制,消息过期策略等都是配置在Namespace上的。
最后,Pulsar灵活的消息传递框架统一了流式和排队数据消费模型,并提供了更大的灵活性。如下图所示,Pulsar保存主题中的数据,而多个团队可以根据其工作负载和数据消耗模式独立使用数据。
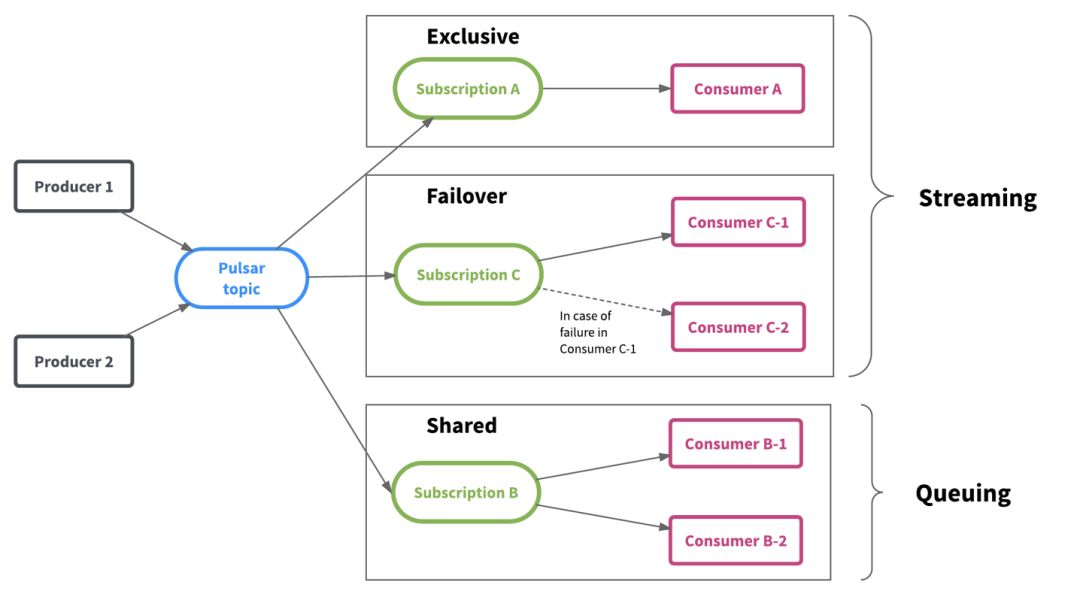
Pulsar提供了灵活的消息模型,支持三种订阅类型:
Exclusive subscription:排他的,只能有一个Consumer,接收一个Topic所有的消息
Shared subscription:共享的,可以同时存在多个Consumer,每个Consumer处理Topic中一部消息(Shared模型是不保证消息顺序的,Consumer数量可以超过分区的数量)
Failover subscription:Failover模式,同一时刻只有一个有效的Consumer,其余的Consumer作为备用节点,在Master Consumer不可用后进行替代(看起来适用于数据量小,且解决单点故障的场景)
Pulsar对数据的看法:分段数据流
Apache Flink是一个流优先计算框架,它将批处理视为流的特殊情况。Flink对数据流的看法区分了有界和无界数据流之间的批处理和流处理,假设对于批处理工作负载,数据流是有限的,具有开始和结束。
对于数据层,Apache Pulsar与Apache Flink的观点相似。该框架还使用流作为所有数据的统一视图,而其分层体系结构允许传统的pub-sub消息传递用于流式工作负载和连续数据处理或分段流的使用以及批量和静态工作负载的有界数据流。
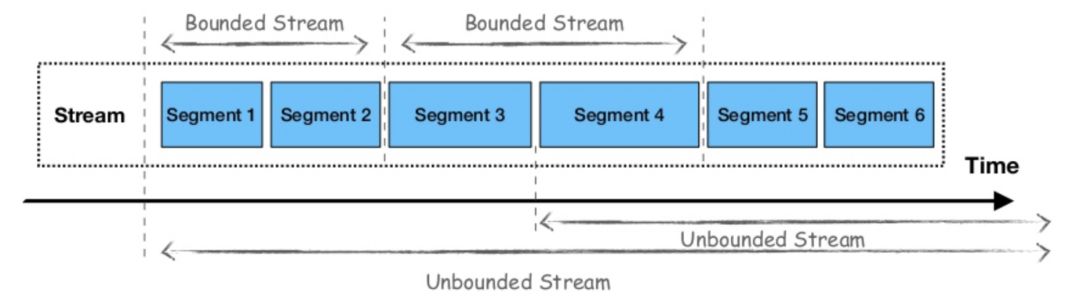
使用Pulsar,一旦生产者向主题(topic)发送数据,它就会根据数据流量进行分区,然后在这些分区下进一步细分 - 使用Apache Bookkeeper作为分段存储 - 以允许并行数据处理,如下图所示。这允许在一个框架中组合传统的pub-sub消息传递和分布式并行计算。
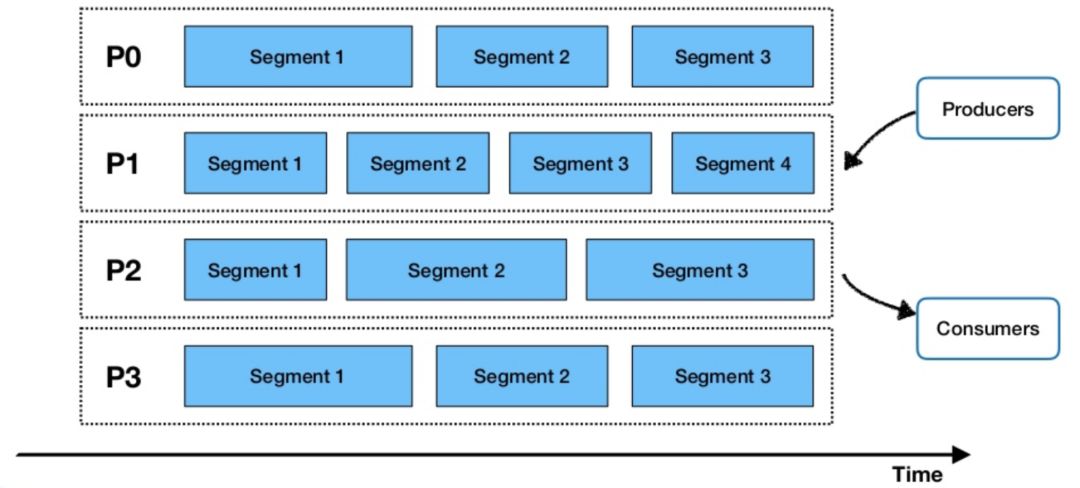
当Flink + Pulsar整合
Apache Flink和Apache Pulsar已经以多种方式集成。在接下来的部分中,我将介绍框架之间的一些潜在的未来集成,并分享可以一起使用框架的现有方法的示例。
首页 下一页 上一页 尾页上一篇:智能家居系统的开源尝试
-
联通大数据携手云粒智慧助力智慧政务转型升级2019-05-28
-
AI+产业大数据助力区域创新体系建设2019-05-28
-
大数据面试真题,来试试你有几斤几两2019-05-28
-
SparkMLlib GBDT算法工业大数据实战2019-05-28
-
泛在电力物联网下大数据发展与应用2019-05-28
-
大数据助智能汽车跑上大马路2019-05-28
-
企业如何实现对工业大数据的预处理?2019-05-28
-
径卫视觉:发挥AI大数据平台优势,用科学管理守护道路交通安全2019-05-28
-
一年5000个项目!华夏幸福产业大数据平台透视汽车投资真相2019-05-28
-
基于HBase的工业大数据存储实战2019-05-28