自动驾驶:ECCV2020|基于关键点的单目3D目标检测
自动驾驶:ECCV2020|基于关键点的单目3D目标检测论文原文:RTM3D:Real-timeMonocular3DDetectionfromObjectKeypointsfor
论文原文:RTM3D:Real-timeMonocular3DDetectionfromObject
KeypointsforAutonomousDriving
目前已有的一些 3D 检测器都是将 3D 边界框到 2D 边界框的几何约束作为重要组件。由于 2D 的边界框只有四条边,仅能提供四个几何约束,这就导致 2D 检测器的一点小错误会极大的影响 3D 检测器的效果。本文的方法通过预测图片中物体 3D 边界框的九个关键点,利用 3D 和 2D 透视图的几何关系恢复 3D 空间中的尺寸、位置和方向。通过这种方法,即使关键点的估计非常嘈杂,也可以稳定地预测对象的属性,使我们能够以较小的架构获得较快的检测速度。训练的方法仅使用对象的 3D 属性,而无需外部网络或监督数据
该方法是第一个用于单眼图像 3D 检测的实时系统,同时达到了 KITTI 基准的最新性能。
论文背景
3D 目标检测是自动驾驶中场景感知和运动预测的基本组件,目前的 3D 检测器都严重依赖于 3D 雷达扫描得到的位置信息。但基于雷达的系统非常昂贵而且不利于编码现在的车辆形状。而单目相机相对便宜更容易应用在现实场景中。本文的研究聚焦于单目 RGB 图片的 3D 目标检测。
单目 3D 目标检测方法大致可以按照训练数据类型被分为两类,一种利用复杂的特征,例如实例分割、车辆形状先验甚至是深度图在多阶段融合模块中选择最佳方案,这些额外的特征需要额外的标注工作来训练一些其他的独立网络,这会消耗大量的运算资源;另外一类方法仅将 2D 的边界框和 3D 物体的属性作为有监督数据,在这种情况下,一个直观的想法是建立一个深度回归网络以直接预测对象的 3D 信息,由于搜索空间较大,这可能会导致性能瓶颈。因此最近有一些工作将 3D 盒顶点的几何约束应用于 2D 盒边缘以细化或直接预测对象参数。但是,2D 边界框的四个边缘仅对恢复 3D 边界框提供了四个约束,而 3D 边界框的每个顶点可能对应于 2D 框中的任何边缘,这需要 4,096 个相同的计算才能得出一个结果。同时,当 2D 检测器的预测甚至有轻微误差时,强烈依赖 2D 框会导致 3D 检测性能急剧下降。因此,大多数这些方法都利用两阶段检测器来确保 2D 边界框预测的准确性,这限制了检测速度的上限。
本文提出了一个无需依赖 2D 检测器的一阶段单目 3D 检测器。首先,通过一个单阶段全卷积架构预测 9 个 2D 关键点,这些关键点包括 3D 边界框的 8 个顶点和中心点的投影点,这 9 个关键点在 3D 边界框上提供了 18 个几何约束。此外,本文还提出了一个全新的用于关键点检测的多尺度金字塔,可以通过软加权金字塔获得最终的关键点激活图。给定 9 个投影点后,下一步是通过对象的位置、尺寸和方向等从这些 3D 点的角度上进行参数化,使重投影误差最小。将重投影误差公式化为 se3 空间中多元方程的形式,可以准确有效地生成检测结果。作者讨论了不同先验信息对基于关键点的方法(如尺寸、方向和距离)的影响。获取此信息的前提条件是不要增加过多的计算,以免影响最终检测速度。本文对这些先验模型进行建模,并提出了一个整体能量函数以进一步改善 3D 估计。
本文的主要贡献有以下几点:
1.将单目 3D 检测转化为关键点检测问题,结合了几何约束来更准确和高效的生成 3D 物体的属性。
2.提出了一种新颖的单阶段多尺度 3D 关键点检测网络,该网络可为多尺度物体提供准确的投影点。
3.提出了一个整体能量函数,可以共同优化先验和 3D 对象信息。
4.根据 KITTI 基准进行评估,本文是第一种仅使用图像的实时 3D 检测方法,与其他方法在相同的运行时间下对比,具有更高的准确性。
论文模型
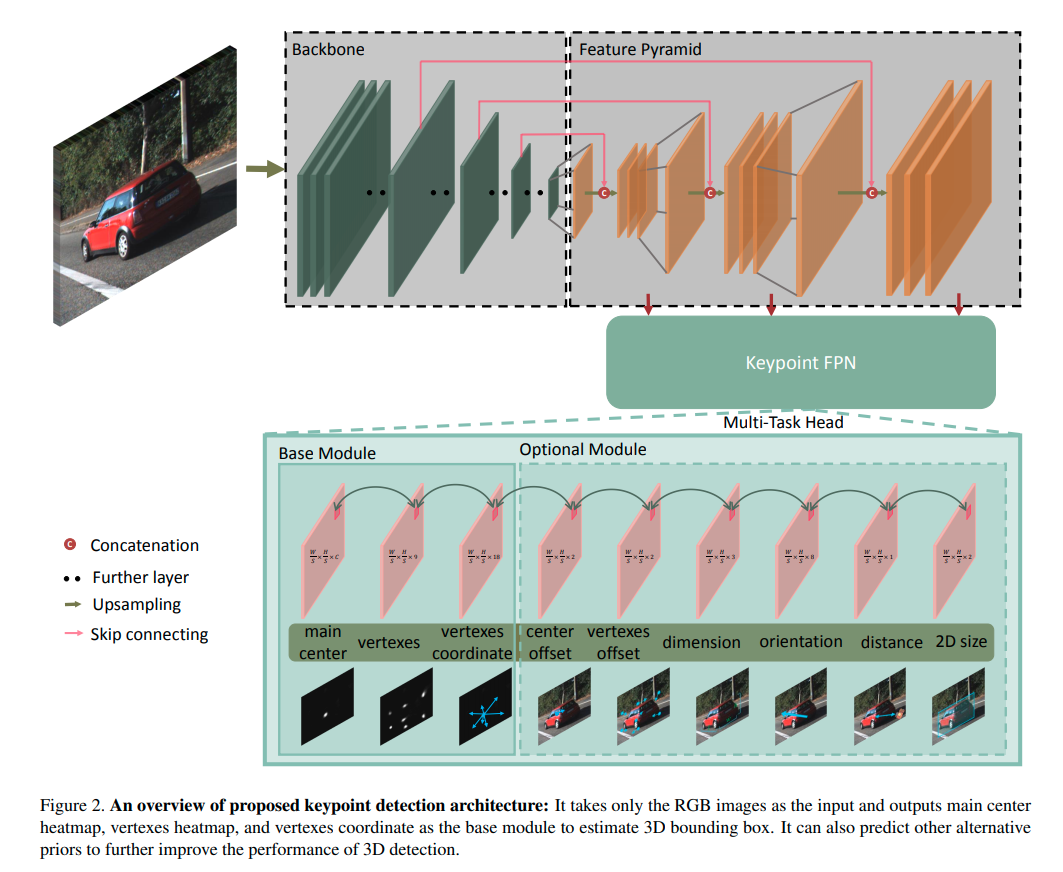
关键点检测网络
本文的关键点检测网络将 RGB 图像当作输入,输出 3D 检测框的顶点及中心点,其包括三个组成部分:骨架、关键点特征金字塔以及检测头,主要架构采用了与 2D 无锚检测器相似的一阶段策略。
为了在速度和准确性之间进行平衡,本文使用两种不同的结构作为主干:ResNet18 和 DLA-34。所有模型均拍摄单个 RGB 图像 I∈R^{W×H×3},并以因子 S = 4 对输入进行降采样。ResNet-18 和 DLA-34 用于图像分类网络,最大降采样因子为 ×32。我们通过三个双线性插值和 1×1 卷积层对瓶颈三次进行上采样。在上采样层之前连接了相应的低级特征图,同时添加了一个 1×1 卷积层以减小通道尺寸。经过三个上采样层后,通道分别为 256、128、64。
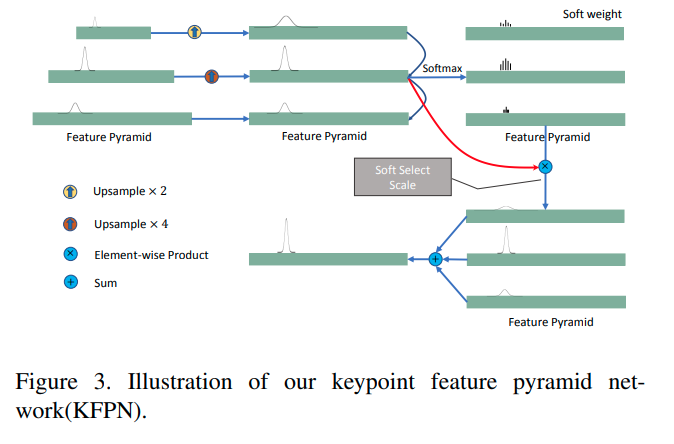
图像中的关键点在大小上没有差异。因此,关键点检测不适合使用特征金字塔网络(FPN)。本文提出了一种新的关键点特征金字塔网络(KFPN),以检测点空间中尺度不变的关键点。假设我们有F个尺度特征图,我们首先调整每个大小f的大小,将其统一为最大的 f 的大小。然后通过 softmax 运算生成软权重,以表示每个尺度的重要性。通过线性加权获得最终的尺度空间得分图:
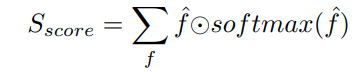
检测头由三个基本组件和六个可选组件组成,可以任意选择这些组件以提高 3D 检测的准确性,而计算量却很少。受 CenterNet 的启发,本文将关键点作为连接所有特征的主要中心 由于在截断的情况下对象的 3D 投影点可能会超出图像边界,因此将更适当地选择 2D 框的中心点。Heatmap 定义为 M,其中 C 是目标种类的数量,另一部分是由顶点和中心点投影出的 9 个点 V,对于一个对象的关键点,本文将回归得到的主中心的局部偏移量 Vc 作为指标。最接近 Vc 坐标的 V 的关键点被作为一个对象的集合。尽管 9 个关键点的 18 个的约束能够恢复物体的 3D 信息,但是越多的先验条件能够增加更多的约束,中心偏移 M_OS,顶点偏移 V_OS 是 heatmap 中对每个关键点的离散误差。
3D 目标的维度 D 方差小容易预测,本文引用基于 Multi-Bin 方法对偏航角 θ 进行回归。将 θ 的余弦偏移和正弦偏移概率在 1 个 bin 中进行分类,并使用 2 个 bin 生成方向特征图,同时对 3D 边框的中心深度Z进行回归。最终的 loss 如下(各部分 loss 的定义参见原文,在此不再赘述):
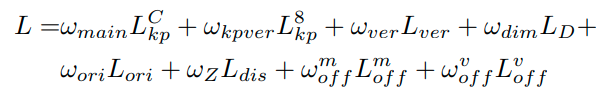
3D边框的估计
得到 9 个特征点 kp、物体尺寸 D、偏航角 θ、中心深度 Z,目标是找出哪一个边框中心点与 2D 关键点 kp 最匹配,这能够最小化 3D 关键点和 2D 关键点的投影损失,并将它和其他先验损失定义为一个非线性最小二乘优化问题:
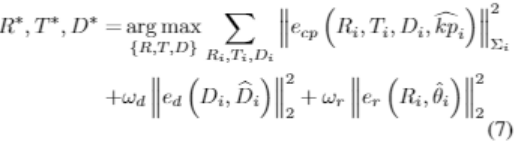
其中 e_cp、e_d、e_r 是相机点、维度先验、方向先验的损失,从 heatmap 中提取的置信度表示为:
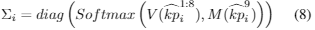
实验论文
本文在 KITTI 数据集上进行了实验。


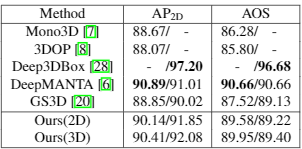
ResNet18 作为 backbone 的时候速度最快,精度已经超过大多数甚至某些双目方法,但仍弱于 M3D-RPN(目前不利用其它训练数据最好的网络),当采用 DLA-34 时速度仍然比别的方法快,而且精度超过 M3D-RPN。
消融实验
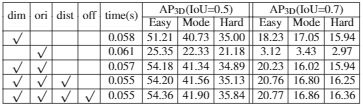
对维度、方向、距离和关键点偏移四个可选项进行了消融实验,四个可选项全部使用时得到了最高的准确率。
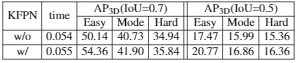
分析了关键点FPN的作用,
同时发现 3D 反向投影的 2D 结果要优于直接对 2D 进行预测。
结论
本文提出了一种用于自动驾驶场景的单眼 3D 目标检测方法。将 3D 检测作为关键点检测问题,并展示了如何通过使用关键点和几何约束来恢复 3D 边界框。本文提出的用于 3D 检测的点检测网络,可以仅使用图像输出 3D 框的关键点和对象的其他先验信息生成稳定且准确的 3D 边界框,而无需包含独立网络和增加额外标注数据,同时可实现实时运行速度。
-
隐私边界无法清晰界定,什么才是合理的隐私期待?2020-09-09
-
雷鸟科技净利大涨88%,多维度长布局成增长关键2020-09-08
-
大唐微电子首家通过交通部“联网电子收费多逻辑通道OBE-SAM模块产品检测”2020-09-07
-
新三板体外诊断之益善生物:肿瘤检测何时能成功变现2020-09-07
-
华为提出适用于弯道的车道线检测方法 CurveLane-NAS2020-09-06
-
科普 | 网络切片技术,5G应用落地的关键!2020-09-04
-
智慧城市:部署威胁检测平台2020-09-03
-
辅助生殖赛道具有高门槛,NGS技术将广泛服务于优孕检测2020-09-02
-
CVPR 2020 |用于3D目标检测的层级图网络2020-09-01
-
突破数字病理诊断关键技术瓶颈,飞利浦IntelliSite平台亮相CHINC 20202020-09-01
-
数坤科技再获2亿元融资,不断探寻医疗AI边界价值2020-08-31
-
深度学习算法新应用:脸部识别检测心脏病,准确率达80%2020-08-28
-
陈根:脸部识别检测心脏病,准确率达80%2020-08-28
-
大规模物联网部署的5个关键注意事项2020-08-27
-
腾讯二季度财报给出「企业数字化」关键词:云服务、小程序2020-08-26