靠追踪肌肉识别表情的“人脸识别”耳机?
靠追踪肌肉识别表情的“人脸识别”耳机?用AI使蒙娜丽莎动起来,甚至是跟着你的表情一起运动,随着技术的发展,这些都已经不是什么新鲜事了。这些面部追踪系统,往往都需要一定精度的摄像头。

用AI使蒙娜丽莎动起来,甚至是跟着你的表情一起运动,随着技术的发展,这些都已经不是什么新鲜事了。

这些面部追踪系统,往往都需要一定精度的摄像头。
但是,如果文摘菌告诉你,这些摄像头其实全都可以撤掉呢?
别急着反驳,这已经被康奈尔大学的研究人员实现了,整个过程他们没有用到过一个面对用户正脸的摄像头,就成功地实现了面部追踪,至于效果,好像也没有差到哪儿去。
按照惯例,我们还是先看看追踪效果如何:

既然没有用到摄像头,那我们来试试戴上口罩的效果:
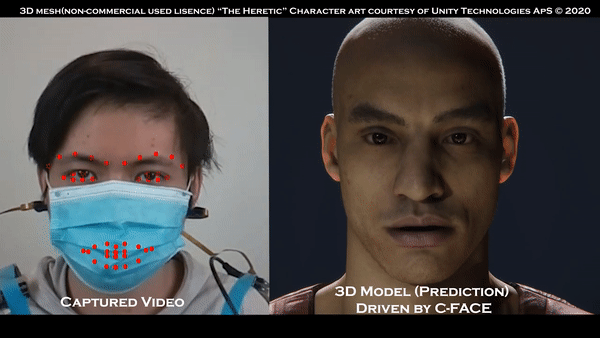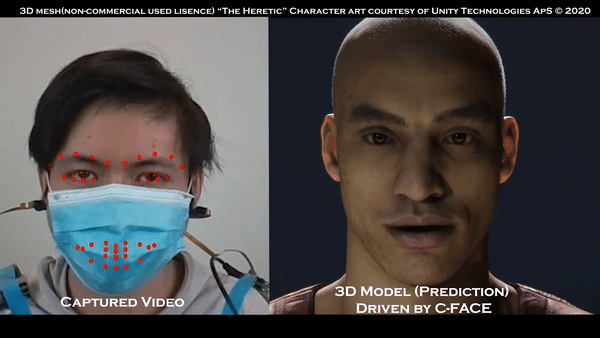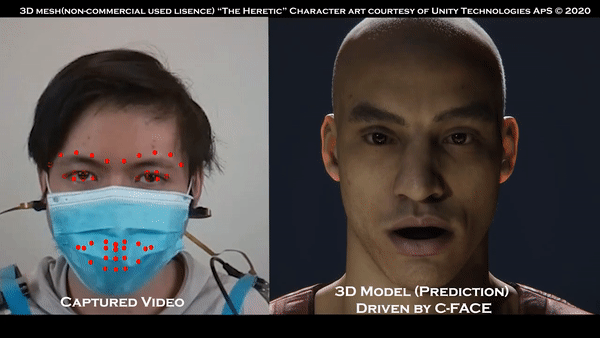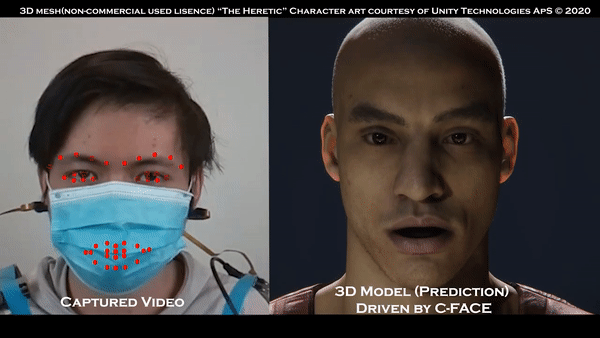
这时候可能有人想问了,不用摄像头,怎么追踪到的面部表情?
文摘菌给一个提示,看到他们戴在耳朵上的仪器了吗?是的,他们主要使用的,其实就是那副耳机,用户的表情就能被实时转换为表情。
这种方法比用摄像头的“传统方法”更好的一点在于,即使戴着口罩,系统也可以追踪用户的面部表情,这样的话人们就不用专门取下口罩了。
这个系统被取名为C-Face(Contour-Face)。
康奈尔大学SciFi实验室主任、C-Face论文的高级作者张铖在一份声明中说:“该设备比任何现有的耳挂式可穿戴技术都更简单、更引人注目,功能也会更强大。”
“在以前的旨在识别面部表情的可穿戴技术中,大多数解决方案都需要在面部上安装传感器,但即使用了如此多的传感器,不少系统最终也只能识别有限的一组离散面部表情。”
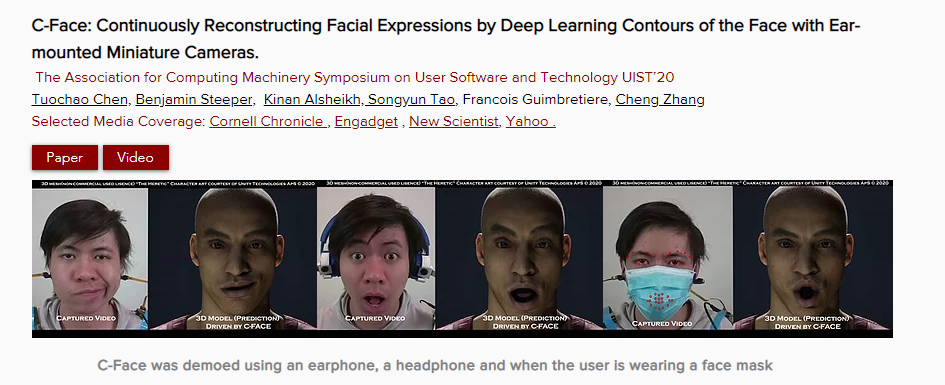

抓取42个特征点,C-Face还支持无声命令和聊天表情发送 在这个项目中,研究人员也不是完全没有用到摄像头,只不过他们用得及其隐蔽。 可能已经有“陈独秀”想要抢答了,注意观察使用者的耳朵下方,左右分别配备了一个RGB摄像头,这些摄像头能够在使用者移动面部肌肉时,记录下脸颊轮廓的变化。
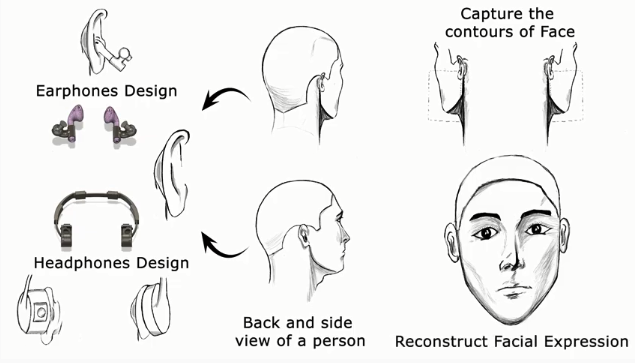
除了入耳式耳机,头戴式耳机也同样可以安装摄像头,进行面部识别工作。

在使用计算机视觉和深度学习模型重建图像后,卷积神经网络能够分析2D图像,将面部特征转换为42个面部特征点,这些特征点分别代表了使用者的嘴巴、眼睛和眉毛的位置和形状。 有了详细的脸部追踪数据,C-Face可以将这些数据转换成八种不同表情,包括中立或愤怒。 不仅如此,C-Face还支持使用面部表情控制音乐应用程序上的播放选项。 手机在桌上充电,但是现在只想摊在沙发上不想动,你甚至不用说出声音,就能播放歌曲:

或者,你在聊天的时候想要发送表情,但是死活找不到表情包了,怎么办? 这个时候,你可以直接做出相关表情,系统就能识别并直接发送出去,简直不要太方便:

不过,由于受到新冠疫情的影响,研究人员目前只在9名参与者的情况下测试了C-Face。尽管数量不大,但表情识别的准确度超过了88%,面部提示的准确度超过了85%。 同时,研究人员发现,耳机的电池容量限制了该系统的持续作用,他们正在计划开发功耗更低的传感技术。 深耕于人机交互领域的华人教授张铖
在这个项目的研发团队中,文摘菌发现了一位华人教授的身影——张铖,他也是这个研发团队的负责人。 根据张铖个人网站介绍,他目前是康奈尔大学计算机和信息科学的助理教授,同时也是未来交互智能计算机接口(Smart Computer Interfaces for Future Interaction,SciFi)实验室主任。

 从南开大学的本科,到以中国科学院软件研究所的优秀毕业生身份毕业,再到前往美国佐治亚理工学院Ubicomp实验室继续深造,张铖始终对普适计算(ubiquitous computing)和人机交互(HCI)怀有浓厚的兴趣。 在中国科学院期间,他就针对有形用户界面、儿童人机交互、音乐界面等进行了初步研究,获得了第一手的研究经验。 在张铖的博士论文中,他介绍了10种用于可穿戴设备的新型输入技术,有些利用了商用设备,有些采用了新的硬件。与大多数人不同,张铖习惯于从头到尾建造传感系统,包括理解物理现象、构建硬件原型、设计形式因素、处理数据和设计算法(机器学习或基于物理的建模)。 截至目前,张铖在人机交互和普适计算领域的顶级会议和期刊上发表了十多篇论文,还获得了两项最佳论文奖,同时他还身怀超过10项美国和国际专利。 如果有同学对人机交互感兴趣,可以多逛逛SciFi实验室主页,他们还有好多有意思的项目~
从南开大学的本科,到以中国科学院软件研究所的优秀毕业生身份毕业,再到前往美国佐治亚理工学院Ubicomp实验室继续深造,张铖始终对普适计算(ubiquitous computing)和人机交互(HCI)怀有浓厚的兴趣。 在中国科学院期间,他就针对有形用户界面、儿童人机交互、音乐界面等进行了初步研究,获得了第一手的研究经验。 在张铖的博士论文中,他介绍了10种用于可穿戴设备的新型输入技术,有些利用了商用设备,有些采用了新的硬件。与大多数人不同,张铖习惯于从头到尾建造传感系统,包括理解物理现象、构建硬件原型、设计形式因素、处理数据和设计算法(机器学习或基于物理的建模)。 截至目前,张铖在人机交互和普适计算领域的顶级会议和期刊上发表了十多篇论文,还获得了两项最佳论文奖,同时他还身怀超过10项美国和国际专利。 如果有同学对人机交互感兴趣,可以多逛逛SciFi实验室主页,他们还有好多有意思的项目~

-
“人脸识别”耳机?!靠追踪肌肉识别表情,华人教授参与研发2020-10-17
-
人脸追踪、双目活体对齐……系统梳理人脸识别开发的硬核技巧2020-10-17
-
iPhone 12人脸识别更快、续航更久2020-10-12
-
支付宝团队回应手机黑产:人脸识别未被突破 受害人没被套到钱和信息2020-10-10
-
人脸识别:只要你的脸还在,你就没有隐私可言?2020-10-03
-
人脸识别技术有被滥用趋势?别多想2020-09-30
-
突围电商“十面埋伏”,人脸识别如何赋能线下商场数字化运营能力?2020-09-30
-
创建一个简单的人脸识别手机APP程序2020-09-22
-
哪些工业视觉识别技术的应用需要边缘计算?2020-09-22
-
实现人脸识别无感通行的密钥:图像质量检测算法2020-09-18
-
北京推出人脸识别垃圾桶,专家:必要性不足2020-09-18
-
人脸识别下的隐私代价有多大?2020-09-16
-
首次加入人脸识别!全系2.0T+9AT,新款凯迪拉克XT4售25.97万元2020-09-15
-
李开复口误风波致歉 人脸识别虽好但用户隐私更重要2020-09-14
-
博观智能ReID车辆识别达到97.59%,刷新多项世界纪录2020-09-07