如何使用Transformer在Twitter数据上进行情感分类
如何使用Transformer在Twitter数据上进行情感分类介绍Transformer的发明最近取代了自然语言处理的世界。transformers是完全无视传统的基于序列的网络
介绍Transformer的发明最近取代了自然语言处理的世界。transformers是完全无视传统的基于序列的网络。RNN是用于基于序列的任务(如文本生成,文本分类等)的最初武器。但是,随着LSTM和GRU单元的出现,解决了捕捉文本中长期依赖关系的问题。但是,使用LSTM单元学习模型是一项艰巨的任务,因为我们无法使其并行学习。
Transformer类似于以编码器-解码器为基础的网络,并在其末尾添加了注意层,以使模型能够根据文本的相关上下文进行有效学习。让我们看看如何使用这个很棒的python包装器。你需要创建一个Twitter开发人员帐户,以便可以访问其API并利用许多不可思议的功能。
请通过此来了解它。
先决条件构建简单的Transformer模型时要考虑到特定的自然语言处理(NLP)任务。每个此类模型都配备有旨在最适合它们要执行的任务的特性和功能。使用简单Transformer模型的高级过程遵循相同的模式。我们将使用库中的文本分类模块来构建情感分类器模型。通过以下代码安装简单的转换器库。pip install simpletransfomers
最好创建一个虚拟环境并进行安装。在安装软件包后,请按照以下链接中提到的步骤来组织你的Twitter开发帐户。设置帐户后,获取帐户的记名令牌并将其保存在YAML文件中,如下所示:
bearer_token: xxxxxxxxxxxxxxxxxxxxxxx
模型对于此任务,我们将使用Kaggle的以下数据集:数据集有两列,一列具有文本,另一列具有相应的情感。让我们可视化数据集及其类分布。

数据集中有以下情感类别:*悲伤,愤怒,爱,惊奇,恐惧,快乐,*你可以在下图中看到其分布
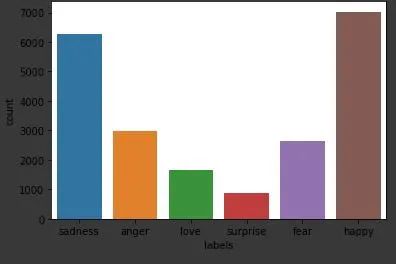
在对数据集进行建模之前,我们可以执行一些基本的预处理步骤,例如清除文本,使用数字对类进行编码等,以便最终的数据帧看起来像下面的图像。

我已将以下内容定义为模型训练的输入配置。我已经使用XL-Net对数据集进行建模,因为它是Transformer的高级版本,可以捕获较长序列的上下文。max_seq_length保持为64,因为在数据集中找到的最大token数为66,如果你希望为更大的文本输入训练模型,可以根据需要将其增加到更大的值。from simpletransformers.classification import ClassificationModel, ClassificationArgs
model_args = ClassificationArgs()
model_args.num_train_epochs = 4
model_args.reprocess_input_data = True
model_args.save_best_model = True
model_args.save_optimizer_and_scheduler = False
model_args.overwrite_output_dir = True
model_args.manual_seed = 4
model_args.use_multiprocessing = True
model_args.train_batch_size = 16
model_args.eval_batch_size = 8
model_args.max_seq_length = 64
model = ClassificationModel("xlnet",
"xlnet-base-cased",
num_labels=6,
args=model_args,
use_cuda=True)
训练模型后,你可以获取验证数据集的指标并评估其性能。如果你之前未进行任何配置,则模型权重将保存在 output/ directory 中。接下来是使用Twitter API获得推文的部分。你可以使用该API的最大推文数量为100,可以通过使用高级帐户进一步增加。可以使用以下代码片段获取特定句柄的tweet。def create_twitter_url(handle, max_results):
mrf = "max_results={}".format(max_results)
q = "query=from:{}".format(handle)
url = "https://api.twitter.com/2/tweets/search/recent?{}&{}".format(
mrf, q
)
return url
def process_yaml():
with open("keys.yaml") as file:
return yaml.safe_load(file)
def create_bearer_token(data):
return data["search_tweets_api"]["bearer_token"]
def twitter_auth_and_connect(bearer_token, url):
headers = {"Authorization": "Bearer {}".format(bearer_token)}
response = requests.request("GET", url, headers=headers)
return response.json()
url = create_twitter_url('user',10)
data = process_yaml()
bearer_token = create_bearer_token(data)
response = twitter_auth_and_connect(bearer_token, url)
text_list = [x['text'] for x in response['data']]
cleaned_text = [re.findall(regex, x)[0] for x in text_list]
上面的代码获取了“user”句柄的Twitter响应,并将获得相应句柄的最新10条推文。清除了这些推文以删除任何表情符号,链接等。例如,让我们看一下一些著名的社交媒体链最近发布的20条推文的情感,以及他们对这些推文的情绪。
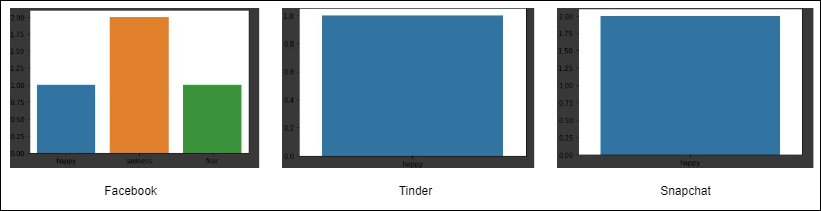
那些著名的社交媒体链的情感计数与其他人相比,Facebook似乎度过了一个美好的一周。本文我们使用Twitter API和Transfer构建了一个简单的情感分类应用程序,你还可以实时进行操作,并进一步扩展此用例,分析任何暴力或悲伤的推特。
无相关信息