如何使用深度学习生成模糊背景?
如何使用深度学习生成模糊背景?概述:介绍我们使用的深度学习模型和ReLu6介绍如何使用深度学习生成模糊背景介绍背景模糊效果是一种常见的图像效果,主要用于拍摄特写镜头上。它可以给我们
概述:
介绍我们使用的深度学习模型和ReLu6
介绍如何使用深度学习生成模糊背景
介绍

背景模糊效果是一种常见的图像效果,主要用于拍摄特写镜头上。它可以给我们的图像增加了一种深度感,突出关注图像的某一部分。为了获得这种效果,我们通常使用一些照片编辑应用程序,例如Photoshop,Gimp,Picsart,Snapseed等,但随着时间的推移,我们在计算机视觉和使用深度学习的图像处理方面取得了显着改善,我们可以使用深度学习来获得这种效果。在本文中,会引导你完成完整的实现以及代码和一些理论方面的知识,以便更好地理解相关内容。
目录
实现原理
我们使用的深度学习模型
ReLu6
实施
得分
结论
1. 实现原理
基本上,我们的整个目标是基于称为图像分割的卷积神经网络的高级实现。我们都熟悉CNN,它用于基于图像输入标签数量图像分类,但是,假设为此必须在给定图像中标识特定对象,我们必须使用对象检测和图像分割的概念。
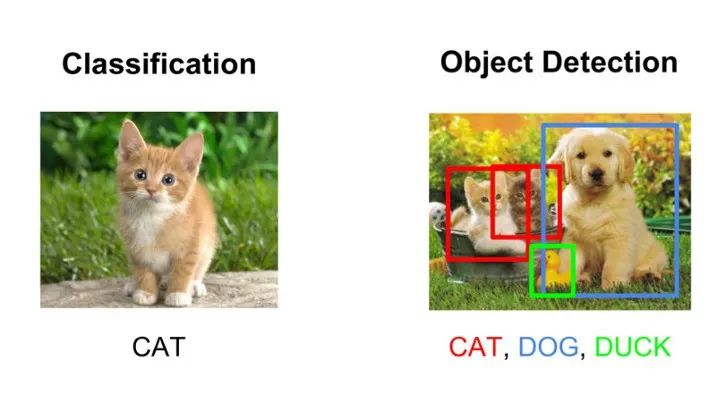
这是图像分类和检测的经典示例,其中如果在单个图像中有多个类别的对象可用,那么我们在进行对象检测的过程中,一旦找到了多个对象的坐标,则给定图像将经过ROIPooling(region of interest pooling),对这些对象进行分类,并在每个标识的对象周围绘制边框。由于边界框仅显示对象在图像内部的位置,所以不会提供有关对象形状的任何信息。简而言之,图像分割是将图像像素分为小部分或片段,并根据相似的信息或属性将它们分组并为其分配标签的过程,这有助于捕获像素级别的非常小的细节。分割会为图像中的每个已识别对象创建一个像素级模板,请看下面的图片,其主要目的是以这种方式训练神经网络,使其可以提供图像的像素级模板。

2. 我们使用的深度学习模型
在了解图像分割概念知乎,接下来让我们看一下要使用的模型,即在coco数据集上训练的mobilenetv2。mobilenetv2是一种轻量级模型,可以在手机等低功耗设备上使用,这是2017年发布的mobilenetv1模型的第二个版本。现在让我们简要了解模型架构。
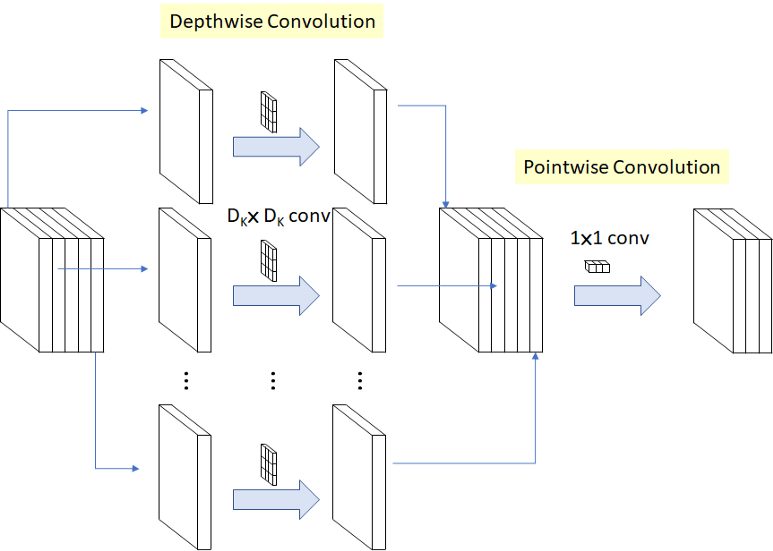
v2是基于v1的,因此它继承了相同的深度方向的可分离卷积,其中包括深度方向的卷积和点方向的卷积,从而降低了卷积操作的成本。深度卷积简单地说,假设一幅图像包含3个通道,那么每个内核将分别在每个通道上迭代。例如,你有一张(10 x 10 x 3)的图像和(3 x 3 x 1)的3个滤波器,那么结果输出将是一个(8 x 8 x 1)这样的滤波器,之后所有其他滤波器的输出滤波器堆叠在一起,形成由(8 x 8 x 3)组成的特征图。在逐点卷积中,我们采用(8 x 8 x 3)的先前特征图,并应用大小为(1 x 1 x 3)的过滤器,如果应用了15个此类滤波器,则最终结果将叠加起来形成(8 x 8 x 15)的特征图。mobilenetv2对v1进行了一些改进,例如实现了反向残差,线性瓶颈和残差连接。
3 4 首页 下一页 上一页 尾页
无相关信息