提升字符串格式化效率的小技巧
提升字符串格式化效率的小技巧一、前言二、最简单的格式化三、测试1:手动格式化数字四、测试2:混合格式化字符串和数字五、sprintf 的实现机制六、总结一、前言在嵌入式项目开发中,
一、前言
二、最简单的格式化
三、测试1:手动格式化数字
四、测试2:混合格式化字符串和数字
五、sprintf 的实现机制
六、总结
一、前言
在嵌入式项目开发中,字符串格式化是很常见的操作,我们一般都会使用 C 库中的 sprintf 系列函数来完成格式化。
从功能上来说,这是没有问题的,但是在一些时间关键场合,字符串的格式化效率会对整个系统产生显著的影响。
例如:在一个日志系统中,吞吐率是一个重要的性能指标。每个功能模块都产生了大量的日志信息,日志系统需要把时间戳添加到每条日志的头部,此时字符串的格式化效率就比较关键了。
天下武功,唯快不破!
这篇文章就专门来聊一聊把数字格式化成字符串,可以有什么更好的方法。也许技术含量不高,但是很实用!
二、最简单的格式化
#include
其中,LONG_MAX 表示 long 型数值的最大值。代码在眨眼功夫之间就执行结束了,但是如果是一百万、一千万次呢?
三、测试1:手动格式化数字
1. 获取系统时间戳函数
我的测试环境是:在 Win10 中通过 VirtualBox,安装了 Ubuntu16.04 虚拟机,使用系统自带的 gcc 编译器。
为了测试代码执行的耗时,我们写一个简单的函数:获取系统的时间戳,通过计算时间差值来看一下代码的执行速度。
// 获取系统时间戳long long getSysTimestamp(){ struct timeval tv; gettimeofday(&tv, 0); long long ts = (long long)tv.tv_sec * 1000000 + tv.tv_usec; return ts; }
2. 实现格式化数字的函数// buff: 格式化之后字符串存储地址;// value: 待格式化的数字void Long2String(char *buff, long value){ long tmp; char tmpBuf[32] = { 0 }; // p 指向临时数组的最后一个位置 char *p = &tmpBuf[sizeof(tmpBuf) - 1]; while (value != 0) { tmp = value / 10; // 把一个数字转成 ASCII 码,放到 p 指向的位置。 // 然后 p 往前移动一个位置。 *--p = (char)('0' + (value - tmp * 10)); value = tmp; }
// 把临时数组中的每个字符,复制到 buff 中。 while (*p) *buff++ = *p++;}
这个函数的过程很简单,从数字的后面开始,把每一个数字转成 ASCII 码,放到一个临时数组中(也是从后往前放),最后统一复制到形参指针 buff 指向的空间。
3. 测试代码int main(){ printf("long size = %d, LONG_MAX = %ld", sizeof(long), LONG_MAX); // 测试 1000 万次 int total = 1000 * 10000; char buff1[32] = { 0 }; char buff2[32] = { 0 };
// 测试 sprintf long long start1 = getSysTimestamp(); for (int i = 0; i < total; ++i) sprintf(buff1, "%ld", LONG_MAX); printf("sprintf ellapse: %lld us ", getSysTimestamp() - start1);
// 测试 Long2String long long start2 = getSysTimestamp(); for (int i = 0; i < total; ++i) Long2String(buff2, LONG_MAX); printf("Long2String ellapse: %lld us ", getSysTimestamp() - start2); return 0;}
4. 执行结果对比long size = 4, LONG_MAX = 2147483647sprintf ellapse: 1675761 us Long2String ellapse: 527728 us
也就是说:把一个 long 型数字格式化成字符串:
使用 sprintf 库函数,耗时 1675761 us;使用自己写的 Long2String 函数,耗时 527728 us;
大概是 3 倍左右的差距。当然,在你的电脑上可能会得到不同的结果,这与系统的负载等有关系,可以多测试几次。
四、测试2:混合格式化字符串和数字
看起来使用自己写的 Long2String 函数执行速度更快一些,但是它有一个弊端,就是只能格式化数字。
如果我们需要把字符串和数字一起格式化成一个字符串,应该如何处理?
如果使用 sprintf 库函数,那非常方便:
sprintf(buff, "%s%d", "hello", 123456);
如果继续使用 Long2String 函数,那么就要分步来格式化,例如:
// 拆成 2 个步骤sprintf(buff, "%s", "hello");Long2String(buff + strlen(buff), 123456);
以上两种方式都能达到目的,那执行效率如何呢?继续测试:
int main(){ printf("long size = %d, LONG_MAX = %ld", sizeof(long), LONG_MAX); // 测试 1000 万 次 const char *prefix = "ZhangSan has money: "; int total = 1000 * 10000; char buff1[32] = { 0 }; char buff2[32] = { 0 };
// 测试 sprintf long long start1 = getSysTimestamp(); for (int i = 0; i < total; ++i) sprintf(buff1, "%s%ld", prefix, LONG_MAX); printf("sprintf ellapse: %lld us ", getSysTimestamp() - start1);
// 测试 Long2String long long start2 = getSysTimestamp(); for (int i = 0; i < total; ++i) { sprintf(buff2, "%s", prefix); Long2String(buff2 + strlen(prefix), LONG_MAX); } printf("Long2String ellapse: %lld us ", getSysTimestamp() - start2); return 0;}
执行结果对比:
long size = 4, LONG_MAX = 2147483647sprintf ellapse: 2477686 us Long2String ellapse: 816119 us
执行速度仍然是 3 倍左右的差距。就是说,即使拆分成多个步骤来执行,使用 Long2String 函数也会更快一些!
五、sprintf 的实现机制
sprintf 函数家族中,存在着一系列的函数,其底层是通过可变参数来实现的。之前写过一篇文章一个printf(结构体指针)引发的血案,其中的第四部分,使用图片详细描述了可变参数的实现原理,摘抄如下。
1. 可变参数的几个宏定义typedef char * va_list;
#define va_start _crt_va_start#define va_arg _crt_va_arg #define va_end _crt_va_end
#define _crt_va_start(ap,v) ( ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) ) #define _crt_va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) ) #define _crt_va_end(ap) ( ap = (va_list)0 )
注意:va_list 就是一个 char* 型指针。
2. 可变参数的处理过程
我们以刚才的示例 my_printf_int 函数为例,重新贴一下:
void my_printf_int(int num, ...) // step1{ int i, val; va_list arg; va_start(arg, num); // step2 for(i = 0; i < num; i++) { val = va_arg(arg, int); // step3 printf("%d ", val); } va_end(arg); // step4 printf("");}
int main(){ int a = 1, b = 2, c = 3; my_printf_int(3, a, b, c);}
Step1: 函数调用时
C语言中函数调用时,参数是从右到左、逐个压入到栈中的,因此在进入 my_printf_int 的函数体中时,栈中的布局如下:

Step2: 执行 va_start
va_start(arg, num);
把上面这语句,带入下面这宏定义:
#define _crt_va_start(ap,v) ( ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) )
宏扩展之后得到:
arg = (char *)num + sizeof(num);
结合下面的图来分析一下:首先通过 _ADDRESSOF 得到 num 的地址 0x01020300,然后强转成 char* 类型,再然后加上 num 占据的字节数(4个字节),得到地址 0x01020304,最后把这个地址赋值给 arg,因此 arg 这个指针就指向了栈中数字 1 的那个地址,也就是第一个参数,如下图所示:
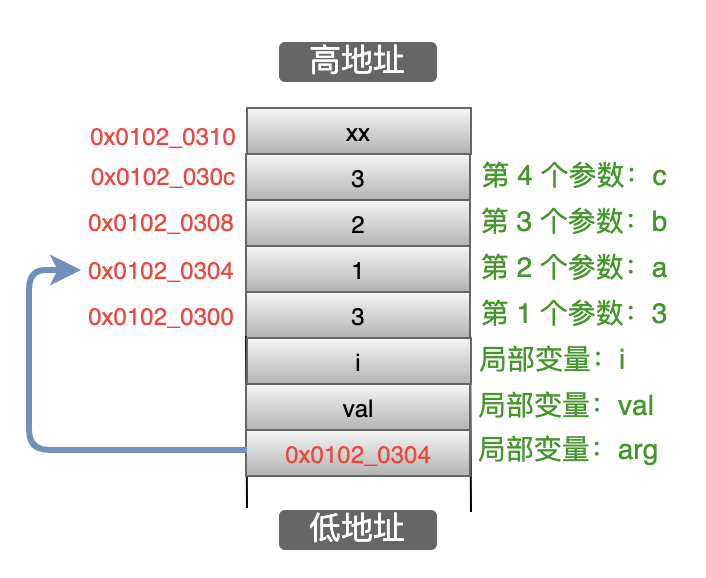
Step3: 执行 va_arg
val = va_arg(arg, int);
把上面这语句,带入下面这宏定义:
#define _crt_va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
宏扩展之后得到:
val = ( *(int *)((arg += _INTSIZEOF(int)) - _INTSIZEOF(int)) )
结合下面的图来分析一下:先把 arg 自增 int 型数据的大小(4个字节),使得 arg = 0x01020308;然后再把这个地址(0x01020308)减去4个字节,得到的地址(0x01020304)里的这个值,强转成 int 型,赋值给 val,如下图所示:

简单理解,其实也就是:得到当前 arg 指向的 int 数据,然后把 arg 指向位于高地址处的下一个参数位置。
va_arg 可以反复调用,直到获取栈中所有的函数传入的参数。
Step4: 执行 va_end
va_end(arg);
把上面这语句,带入下面这宏定义:
#define _crt_va_end(ap) ( ap = (va_list)0 )
宏扩展之后得到:
arg = (char *)0;
这就好理解了,直接把指针 arg 设置为空。因为栈中的所有动态参数被提取后,arg 的值为 0x01020310(最后一个参数的上一个地址),如果不设置为 NULL 的话,下面使用的话就得到未知的结果,为了防止误操作,需要设置为NULL。
六、总结
这篇文章描述的格式化方法灵活性不太好,也许存在一定的局限性。但是在一些关键场景下,能明显提高执行效率。
如果文中演示代码有什么问题,或者你有更好的方法,欢迎分享给大家!
无相关信息