打开混淆虚拟与现实的潘朵拉魔盒
打开混淆虚拟与现实的潘朵拉魔盒打开混淆虚拟与现实的潘朵拉魔盒——生成式对抗网络简述投稿作者:极链科技AI实验室王晓平你是否曾设想过这样的场景:当你坐在电脑前,一边品尝着清香的茶饮,
打开混淆虚拟与现实的潘朵拉魔盒
——生成式对抗网络简述
投稿作者:极链科技AI实验室王晓平
你是否曾设想过这样的场景:当你坐在电脑前,一边品尝着清香的茶饮,一边饶有兴致地在网页上浏览着一张张精彩的图片,从表情丰富的清晰人脸,到色彩艳丽的旖旎风光,还有姿态各异的动物萌宠,等等,一切都是那么的赏心悦目!然而,当你接下来突然被告知,所有的这一切都是由计算机生成的虚拟照片时,你会否大吃一惊转而不敢相信?毕竟,这些照片是如此的栩栩如生!现如今,这样的情形已不再是梦幻,例如,thispersondoesnotexist.com就是这样的一个虚拟人脸生成网站,当用户进入网站后,每一次刷新都可以得到网站即时生成的一张逼真的“人脸”照片,然而,正如该网站名所指的涵义:在现实中,This person does not exist!那么,这种无中生有的神奇效果究竟是如何实现的呢?该网页同时在右下角也注明了:“Produced by a GAN (generative adversarial network)”。OK,本文的主角——生成式对抗网络(GAN)正式登场。
2014年,加拿大蒙特利尔大学的Ian J. Goodfellow在《Generative Adversarial Nets》一文中正式提出了生成式对抗网络,其基本思想就是基于两个模型:一个生成器和一个判别器。判别器的任务是判断一张给定的图片是真实的还是虚假的,而生成器的任务则是生成与真实图片相似的图片以尽可能骗过判别器。打个比方,生成模型类似一个假币制造团伙,其任务是生产和使用假币,而判别模型则类似金融警察,其职责是发现和查处假币。原始的GAN公式如下式所示,G、D分别为生成器、判别器,x为真实数据,z为噪声数据,在对值函数V进行最大、最小化约束下,生成器和判别器交替训练优化,在此过程中,生成器不断提升“造假”能力,直至判别器无法区分真币和假币的程度,此时GAN训练完成。
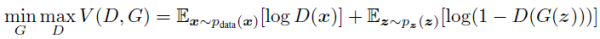
相比于其它模型,为什么GAN一经提出就会受到如此之高的关注热度?从本质上说,GAN的真正强大之处在于开创了一种新的对抗式学习模式,大大提高了对数据分布的学习能力,甚至可在一定程度上认为它赋予了机器一种类似想象力的能力,能够展示出诸多炫目的生成效果,也正是因为这种强大之处,GAN入选了《麻省理工科技评论》 2018 年全球十大突破性技术,而近年来掀起的以其为基础的各种改进或创新研究的热潮也推动了GAN技术的迅速发展。下面本文就将对GAN的发展进行简要的介绍,总体上,这一发展主要体现在以下几方面:
一、图像风格转换方面

一百多年前,当莫奈在春光明媚的塞纳河畔画下这幅油画时,当时他眼前的景象究竟是怎样的?现实的风景是否如同画作所描述的一般优美?要想认真回答这个问题的确很难,因为目前我们还无法乘坐时光机器穿越时空去感同身受,但是,我们可以使用具有风格转换功能的GAN来将莫奈的油画转换为照片风格,从而近似地去感受当时的真实场景。风格转换的酷炫效果使得GAN大放异彩,在这方面,典型的有 pix2pix、CycleGAN、DiscoGAN、DualGAN等,其中,pix2pix解决了成对图像训练的风格转换问题,CycleGAN、DiscoGAN、DualGAN则从训练集合的高度,通过定义循环损失函数解决了非成对图像训练的风格转换问题,虽然在风格转换效果方面稍逊于pix2pix,但却节省了大量的样本准备时间,从而大大降低了将GAN投入实际应用的门槛。
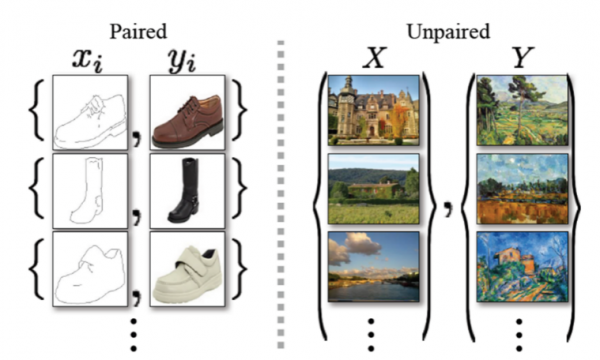
成对训练图像(pix2pix)与非成对训练图像(CycleGAN)

CycleGAN
在风格转换的实际应用过程中,随之也出现了新的问题如:无论是Pix2Pix还是CycleGAN等,都是从一个领域到另一个领域的转换,当有多种不同领域的风格转换需求时,就需要对每一种领域转换都从头开始训练一个新模型来解决,这在实际使用时无疑将相当地麻烦和低效,鉴于此,StarGAN应运而生,其贡献是提出了高效的多领域转换的统一算法框架。下图是StarGAN的效果,在同一种模型下,可以进行多种图像风格转换任务,如改变头发颜色、性别、年龄、肤色等。

StarGAN
二、超分辨率图像生成方面
超分辨率是计算机视觉的一个经典领域,旨在从观测到的低分辨率图像重建出相应的高分辨率图像,它在卫星遥感图像、图像复原等诸多领域都有着重要的应用价值,而GAN的相关研究也进一步推动了这一领域技术的发展。典型的有PG-GAN、BigGAN、pix2pixHD、SR-GAN等,例如,来自NVIDIA的PG-GAN论文,提出以一种渐进增大生成器和鉴别器的方式训练GAN,从最初的4x4低分辨率开始,随着训练的进行,不断添加新的层对越来越精细的细节进行建模,最终达到1024x1024分辨率,实现了效果令人惊叹的生成图像。

PG-GAN
三、生成的可解释性方面
虽然GAN的对抗式学习机制带来了惊艳的图像生成效果,但是刚开始人们对于GAN的生成过程缺乏行之有效的干预手段,因此,研究者们在这方面进行了一系列努力,设法利用控制变量对生成过程进行监督,代表性的工作有InfoGAN、CGAN等,其中,InfoGAN提出将生成器的输入分解为不可压缩的噪声和具有不同意义的潜在控制变量,然后通过调节潜在控制变量来引导生成器生成具有不同方向、不同字体宽度的图像。

InfoGAN
MIT的研究者们通过对网络进行分解,并观察特定单元在激活或关闭时对生成结果的影响来实现对GAN的可视化理解(如GAN DISSECTION图),进而在此基础上实现了高效绘画,仅需轻松操作鼠标,GAN就可以在鼠标划过的地方绘制或擦除树木、草地、门、天空、云朵、砖墙、圆屋顶等景物。

GAN DISSECTION
四、其它方面
除了上述方面,GAN和其它方面技术的结合也展现了相当不错的效果,例如,加州大学伯克利分校的研究人员利用姿态估计技术和GAN实现了不同人之间的动作迁移“do as I do”,即使你完全不会跳舞,但借助这项技术,只需预先输入一段善舞者姿态优美的舞蹈视频,然后再输入你本人的随意动作视频,经过姿态估计和网络训练、视频生成后,你立马就可变身为生成视频里翩翩起舞的绝对主角。所以,在GAN的助力下,不会跳舞?不存在的!

do as I do
其它的还有能够实现不同人之间声音转换的starGAN-vc,提高训练的稳定性方面如WGAN、WGAN-GP、SNGAN,隐私保护方面如宾夕法尼亚大学利用AC-GAN生成的虚拟临床数据进行共享以满足保护参与者隐私的需求,等等。
GAN技术的迅速发展在为我们带来诸多欣喜成果的同时,其出色的图像生成能力也使我们难以对诸如“呈现在你眼前的究竟是虚拟OR现实?”之类的问题给出准确的答案,因此,眼见也未必为实。一旦GAN的这种能力被别有用心者利用,将会造成难以预见的负面影响,例如2017年底网络上出现的基于GAN的换脸视频就带给了世人恐慌和震惊。混淆虚拟与现实之间界线的潘朵拉魔盒已经打开,应引导人们以造福学习、工作、生活为目的正确合理地使用这项技术,不断地让魔盒带给我们惊喜和希望!
无相关信息