自动驾驶汽车的端到端学习
自动驾驶汽车的端到端学习研究人员将使用udacity提供的模拟器,模拟车前部配有3个摄像头,可记录视频以及与中央摄像头对应的转向角。行为克隆的本质是克隆了驱动程序的行为。本文的实验
研究人员将使用udacity提供的模拟器,模拟车前部配有3个摄像头,可记录视频以及与中央摄像头对应的转向角。

行为克隆的本质是克隆了驱动程序的行为。本文的实验思路是根据驾驶员驾驶的训练数据训练卷积神经网络(CNN)以模拟驾驶员。
NVIDIA曾发布了一篇题为End to End Learning for Self-DrivingCars 的文章,他们训练CNN将原始像素从单个前置摄像头直接映射到转向命令。实验结果令人非常震惊,汽车学会了在有或没有车道标记的地方道路上或者在具有最少量训练数据的高速公路上行驶。本次实验,研究人员将使用udacity提供的模拟器,模拟车前部配有3个摄像头,可记录视频以及与中央摄像头对应的转向角。
收集数据
模拟器有2个通道:第一个通道非常容易,曲线较小且很少,第二个通道很难,有许多曲线和陡峭的山坡。
研究人员将使用来自两个轨道的训练数据:
1.研究人员将驾驶两条车道,将车保持在车道的中心位置。研究人员每人开车2圈。
2.研究人员将在两条车道上各开一圈,并试图漂移到两侧,或试图转向车道的中心。这将为研究人员提供模型校正的训练数据。

图分别为左、中、右视角
捕获的数据包含左图像,中心图像和右图像的路径,转向角度,油门,中断和速度值。

注意:研究人员将使用所有左,中,右图像。研究人员将通过一些调整来矫正left_image的转向角度。同样,研究人员将通过一些调整来矫正right_image的转向角度。
数据不平衡
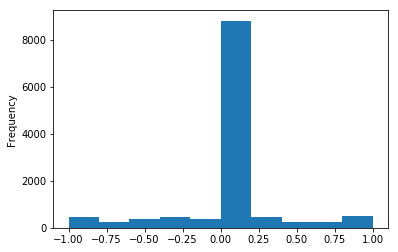
转向角直方图
上面的直方图显示了训练数据的不平衡。左转弯的数据多于右转弯的数据。研究人员将通过随机翻转训练图像并将转向角度调整为steering_angle来补偿这一点。
此外,大多数转向角集中在0-0.25左右,研究人员没有太多的数据来获得更大的转向角。研究人员将通过一些像素水平和垂直地随机移动图像并相应地调整转向角来补偿这一点。
数据扩充
研究人员使用以下增补:
1.随机翻转一些图像并将转向角度调整为steering_angle
2.通过一些像素水平和垂直地随机移动图像,并使用小的调整因子调整转向角度。
3.路上有树木,柱子等阴影。因此,研究人员将为训练图像添加一些阴影。4.研究人员会随机调整图像的亮度。
以上这些是标准的OpenCV调整,代码可以在GitHub存储库中找到。(详见文末链接)
应用增强后,下面是一些训练图像的输出。

前处理
本文期望图像的输入尺寸为66 * 200 * 3,而来自训练的图像尺寸为160 * 320 * 3。此外,纸张期望将输入图像从RGB转换为YUV颜色空间。因此,研究人员将从输入图像裁剪上部40像素行和下部20像素行。此外,作为预处理的一部分,研究人员将裁剪的图像大小调整为66 * 200 * 3大小并将其转换为YUV色彩空间。
模型
这是本文中描述的PilotNet模型:

该模型具有以下层:
①标准化层(硬编码)除以127.5并减去1。
②3个卷积层,24个,36个,48个过滤器,5 * 5内核和2个步幅。
③2个卷积层,64个滤波器,3 * 3内核和步幅1。
④展平层
⑤3个完全连接的层,输出尺寸为100,50,10
⑥和输出转向角的最终输出层。
研究人员将使用Mean Squared Error(MSE)作为损失函数和优化器,并进行EarlyStopping回调。研究人员试图训练它40个epoch,它在36个epoch停止。

训练60个epoch的模型,结果如下:

突出的特点:
1. 在每个图层中,对要素图的激活进行平均。
2.最平均的地图按比例放大到下面图层的地图大小。使用反卷积完成放大。
3.然后将来自较高级别的放大的地图与来自下层的平均地图相乘。
4.重复步骤2和3直到达到输入。
5.具有输入图像大小的最后一个掩模被标准化为0.0到1.0的范围。
以下是可视化图,显示输入图像的哪些区域对网络的输出贡献最大。

在应用上述方法之后,下面是显著的特征结果:

图突出的车道标记
结论
PilotNet是一个非常强大的网络,从驾驶员学习输出正确的转向角度。对显著物体的检查表明,PilotNet学习了对人类“有意义”的特征,同时忽略了与驾驶无关的摄像机图像中的结构。此功能源自数据,无需手工标记。
无相关信息