对于眼睛,我们以类似的方式进行搜索,但将搜索范围缩小到面部矩形:eyes = eyes_cascade.detectMultiScale(img[y:y+h, x:x+w])for (ex, ey, ew, eh) in eyes: cv2.rectangle(img, (x+ex, y+ey), (x+ex+ew, y+ey+eh), (255, 255, 255), 1)成啦!

虽然这是预期的结果,但我们会遇到很多其他方面的问题。很多时候,我们没有正面和清晰的人的脸,甚至……没有眼睛:

眼睛是被白色包围的黑色污点:
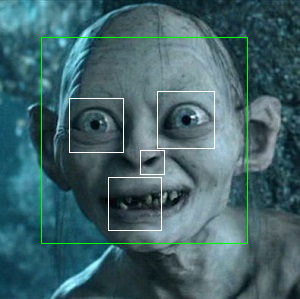
此处有4只眼,仅检测到3只眼:

矫正脸部通过计算两只眼睛之间的角度,我们可以拉直脸部图像(这很容易)。计算后,我们仅需两个步骤即可旋转图像:rows, cols = img.shape[:2]M = cv2.getRotationMatrix2D((cols/2, rows/2), <angle>, 1)img_rotated = cv2.warpAffine(face_orig, M, (cols,rows))

裁剪脸部为了帮助我们的神经网络完成人脸分类任务,最好去掉背景、衣服或配饰等外部干扰信息。在这种情况下,裁剪脸部是一个很好的选择。我们需要做的第一件事是从矫正的人脸图像中再次得到人脸矩形。然后我们需要做一个步骤:我们可以按原样裁剪矩形区域,或者添加一个额外的填充,这样我们可以获得更多的空间。这取决于要解决的具体问题(按年龄、性别、种族等分类);也许你想要更多的头发;也许不需要。

最后,裁剪(p表示填充):cv2.imwrite('crop.jpg', img_rotated[y-p+1:y+h+p, x-p+1:x+w+p])看!这张脸是孤立的,几乎可以进行深度学习了

图像缩放神经网络需要所有的输入图像具有相同的形状和大小,因为GPU在同一时间对一批图像应用相同的指令,以达到超级快的速度。我们可以动态地调整它们的大小,但这可能不是一个好主意,因为在训练期间将对每个文件执行多个转换。因此,如果我们的数据集有很多图像,我们应该考虑在训练阶段之前实现批量调整大小的过程。在OpenCV中,我们可以使用resize()函数执行向下缩放和向上缩放,有几种可用的插值方法,指定最终尺寸的例子:cv2.resize(img, (<width>, <height>), interpolation=cv2.INTER_LINEAR)为了缩小图像,OpenCV建议使用INTER_AREA插值,而要放大图像,可以使用INTER_CUBIC(慢)或INTER_LINEAR(快,效果仍然不错)。最后是质量和时间之间的权衡。我做了一个快速的升级比较:




