南京大学提出基于关键帧移动点法实现行为动作流管检测
南京大学提出基于关键帧移动点法实现行为动作流管检测From:Arxiv 编译:T.R时空行为检测是计算视觉领域重要的研究方向,在安防监控、视频标注、运动分析等方面具有重要的应用。现

From:Arxiv 编译:T.R
时空行为检测是计算视觉领域重要的研究方向,在安防监控、视频标注、运动分析等方面具有重要的应用。现存的行为动作流检测方法大多针对独立帧进行检测,而后进行帧间运动衔接,虽然有基于片段的短时行为检测,但却在检测精度、计算资源消耗和稳定性上还面临着一系列问题。
为了实现更加准确高效的视频行为检测,来自南京大学的研究人员提出了一种移动中心检测器(moving center detector)的架构,通过将行为实例转化为运动点轨迹来简化运动信息并辅助行为流管检测(action tubelet detection),在运动实例中心帧检测与分类、相邻帧运动偏移估计以及目标实例检测框回归的共同努力下实现了可达25fps的高效行为流管检测,同时保证了长时间视频级行为检测的流管融合精度,在帧级和视频级任务上都取得了优异的mAP结果。
基于运动点的行为检测
这一工作的主要目标在对短视频帧序列进行行为流管(action tubelt,ACT)检测。视频中实例的运动信息天然地描述了人类的运动行为,所以每一个动作行为实例可以被描述为一系列运动点的轨迹,同时也可以基于轨迹来实现行为分类。在这样独特的视角下,研究人员将ACT表示为短视频帧序列中关键帧中心点,以及相邻帧中实例中心相对于其中心点的偏移量。
为了实现有效的行为管道检测,研究人员将整个任务分解为了三个相对简单的子任务,包括定位关键帧中的目标中心点、估计相邻帧中实例相对于中心点的位移,并在每一帧计算出的新中心点周围实现实例包围框的回归计算。解耦后的框架不仅更为紧致,优化也更为容易,同时也提高了检测的精度与效率。
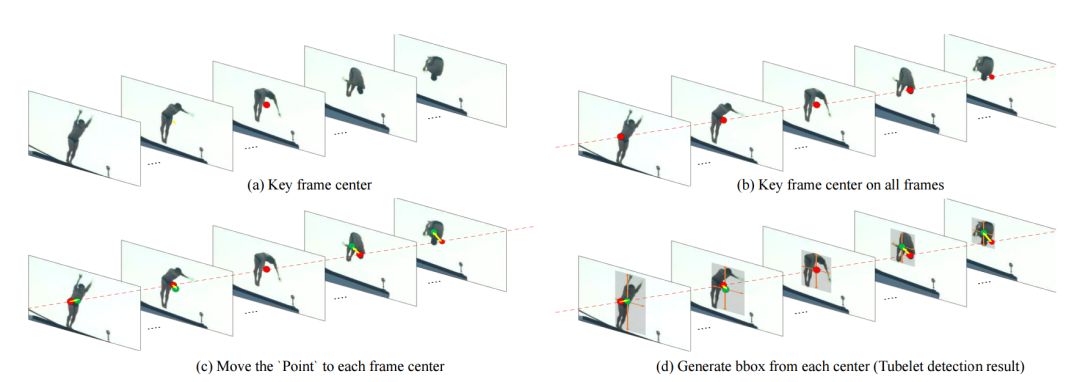
模型架构主要分为四个部分,短视频片段帧被送入主干网络进行特征抽取,而后将特征分别送入三个子任务分支进行处理。其中中心分支用于检测关键帧中的动作中心点和动作分类;移动分支针对所有帧检测动作相对于其中心点的偏移量;bbox分支则用于为每一帧预测相对于其动作中心的实例包围框。这种设计使得三个子任务可以有效协作生成ACT检测结果。最终通过将这些ACT结果进行衔接可以得到视频级别的长程行为检测结果。
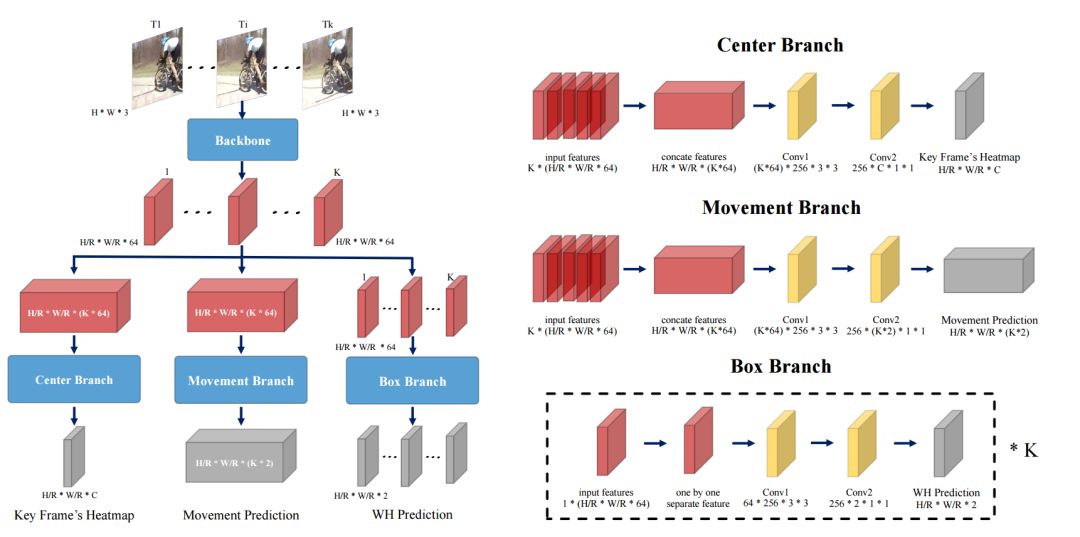
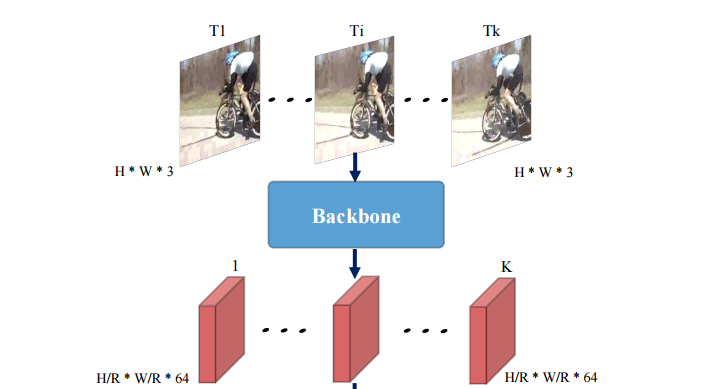
MOC-detector
模型的第一部分是从输入视频序列中抽取特征的主干网络。其中输入为K幅WxH大小的帧,输出为W/rxH/rxKx64的特征,r为空间下采样率。为了保障输入序列的时序结构在时间维度上保持了原来的帧数。在对比了多种网络后,基于精度与效率的权衡研究人员选择了DLA-34作为抽取特征的主干网络。这一架构采用了编码器-解码器架构来从每一帧中独立地抽取特征,并在空间上进行4倍的下采样,抽取的特征被后续三个分支共享。
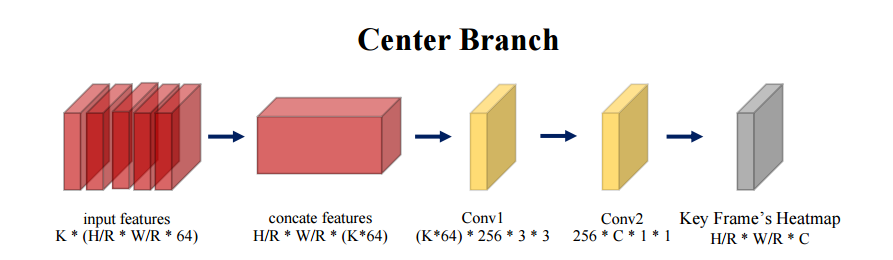
中心预测分支
中心预测分支的主要目的在于从中央关键帧预测出行为流管的中心,并识别出行为的分类。为了从关键帧中检测出行为实例的中心,需要中心分支有效地抽取时域信息来进行动作识别。所以这一部分主要由时域模块构成来估计动作中心。基于W/r×H/r×K×64的视频特征估计出W/r×H/r×C的中心热力图L? ,其中C代表了行为类别的数目,L? 值代表了在(x, y)位置检测到某种行为实例的似然大小,更高的值意味着更大的可能性。为了有效的捕捉时域结构,研究人员使用了3D全卷积操作和sigmoid非线性激活来估计中心热力图。
位移估计分支
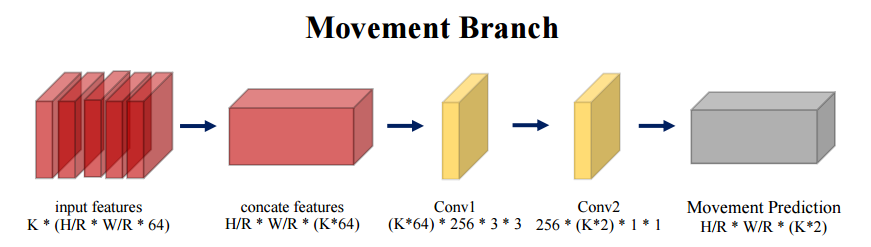
模型的第二部分将针对所有帧,联系相邻帧与关键帧来估计出相对于中心的偏移。首先需要将中央关键帧的中心点平移到所有相邻帧中,而后估计出相邻帧中实例中心相对于关键帧中心的偏移。位移分支同样利用了时域信息来估计出中心点的偏移量,其输入特征为共享的W/r×H/r×K×64的视频特征,输出位移预测图M为W/r×H/r×2K,其中2K代表了K帧上中心分别在x,y方向上的位移。在给定关键帧中心(xkey,ykey)的情况下,Mxkey,ykey,2j:2j+2 编码了从关键帧到第j帧的中心位移。
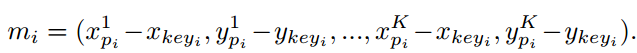
为了有效地捕捉动作中心的移动,研究人员提出了三种不同的实现方法。一种是基于累积移动策略来连续地预测相邻帧间的位移而不是相对于关键帧的位移,但这种方法在预测的时候会带来累积误差影响精度。第二种方法是基于代价空间估计中心位移,通过构建当前帧与关键帧的代价空间直接计算中心位移,但代价空间的构建是的这种方法的精度和速度都没有太好的表现;第三种方法就是本文中使用的中心移动法,通过利用三维卷积操作来直接回归出当前帧与关键帧之间的中心位移,这种策略虽然简单但是在实验中却得到了良好的精度和计算效率。
bbox估计
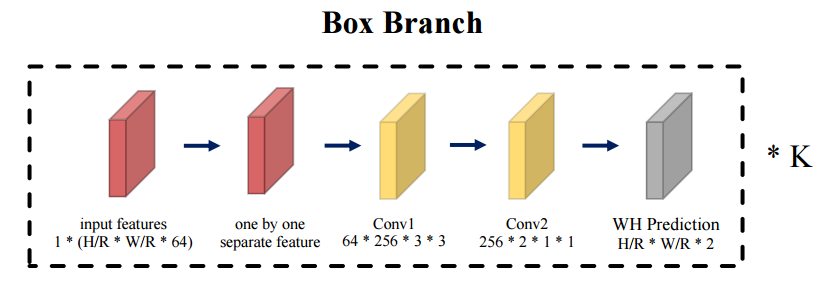
包围框估计分支主要基于每一帧计算出的中心点,聚焦于帧的空间信息来对其中的动作实例进行检测,并回归出包围框的长宽。包围框分支是行为流管检测的最后一步,主要集中于对于行为实例空间信息的分析。与先前两个部分不同的是,这一部分假设bbox 检测只依赖于当前帧的信息。
研究发现时域信息无助于与分类无关bbox的回归结果,而只会带来而外的计算负担。这一分支针对每一帧进行bbox估计,直接估计出框的大小和形状预测图S? ∈ W/r×H/r×K×2,其值定义了在第j帧中的对应位置中心位于(x, y)bbox的大小。
行为管道衔接
在通过MOC检测器得到了短序列片段的结果后,就可以实现长程视频级行为流管的检测了。虽然可以改变k来适应长程多帧的视频,但由于GPU的显存限制是的K的最大帧数不能超过10,在对视频片段进行检测后需要利用衔接衔接算法将不同片段间的动作微管(tubelet)进行融合实现视频级行为管道(tube)检测。
在融合过程中使用了与先前方法相同的衔接算法(linking algorithm),并通过初试步骤的非极大值抑制、融合步骤的有条件衔接、终止步骤的判断来实现视频级别的行为管道检测。这一衔接算法与ACTdetection中的算法相同。附注 ACT-detecitor;Action Tubelet Detector for Spatio-Temporal Action Localization
实验结果
在构建好整套行为管道检测体系后,研究人员在两个较为常用的动作行为数据集上进行了训练和测试,主要包括了UCF101数据集和HMDB51数据集的子集。他们还提出了帧级别的AP和视频级别的AP指标进行比较,其中帧级别与衔接算法独立,注重bbox的回归精度,而视频级别与所有帧相关并与衔接算法紧密联系。而后通过定量和定性的分析对MOC检测器中各个部分和每个分支的性能进行了有效的消融性分析。
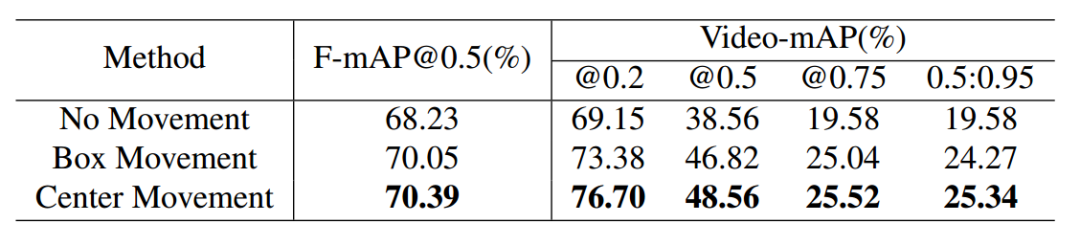
研究人员首先对比了三种不同行为微管检测的策略,分别是
无位移(no movement)
包围框位移(box movement)
中心平移(center movement,MOC)
其中无位移的策略假设主体在局域帧内的中心位移相较于动作幅度来说很小,它直接去掉了位移分支,直接为每一帧基于关键帧中心生成bbox,所有的bbox共享相同的中心仅仅尺寸不同。
包围框进行位移的策略假设bbox的尺寸对中心点位置不敏感,它首先基于关键帧中心点回归出bbox,而后再根据位移分支的预测结果对每一帧bbox进行移动。
MOC策略则是本文中所采用的方法,它认为目标的中心是会变化的,中心的变化也会带来bbox尺寸的变化。利用位移分支的预测结果将每一帧的中心点从关键帧中心移动到自身的动作中心点上来,而后基于自身的中心来计算bbox。它与包围框移动策略不同在于它们基于不同的中心点生成bbox,中心点方法基于当前帧中心生成而包围框方法则基于关键帧中心生成。
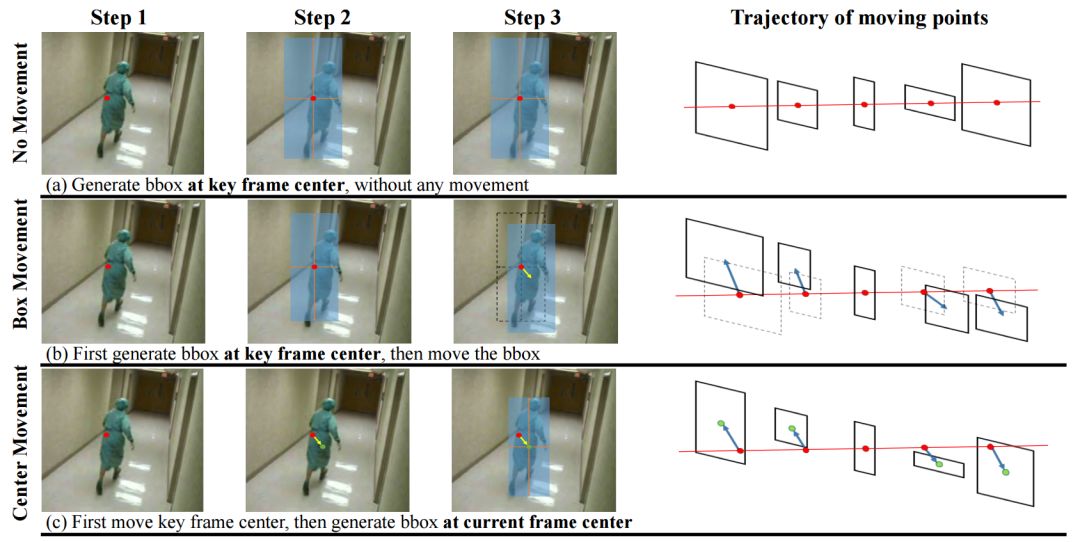
下图显示了三种策略的检测结果,可以看到无位移策略的bbox为了包围整个目标其尺寸更大,而通过调整每一帧中心点的位置和尺寸则有效地提高了非关键帧目标的检测精度。下图显示了MOC方法检测出的bbox其IoU更高,针对较远的非关键帧移动策略的优势更为明显。
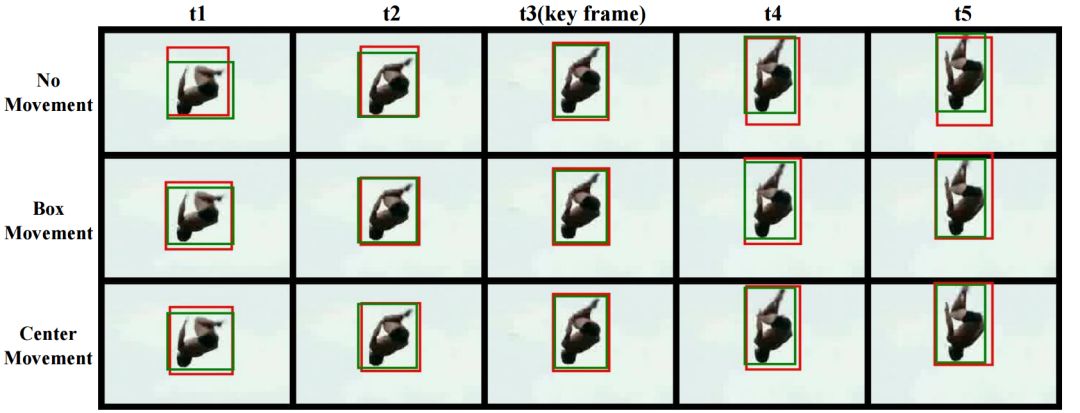
下表中同时显示了包围框移动策略和中心移动策略的差异,MOC方法能够更有效地适应运动目标的检测。
此外还分析了位移分支的不同设计策略,包括基于关键帧的累积位移策略,基于代价空间的移动策略,基于中心的移动策略。下表显示了三种方式的结果。
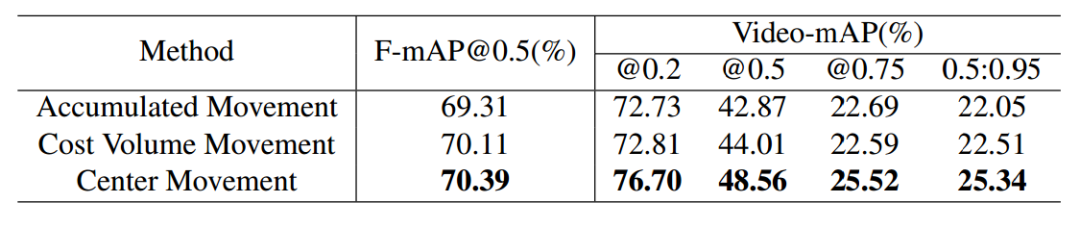
可以看到由于累积误差的影响,累积位移策略表现较差;同时由于代价空间计算仅仅依赖于当前帧与关键帧的相关性图,而确实了整个序列的信息造成了精度下降,此外代价空间的计算只包含了相关性而无额外参数使得其收敛较为困难,所以这两种方式都弱于中心位移的策略。
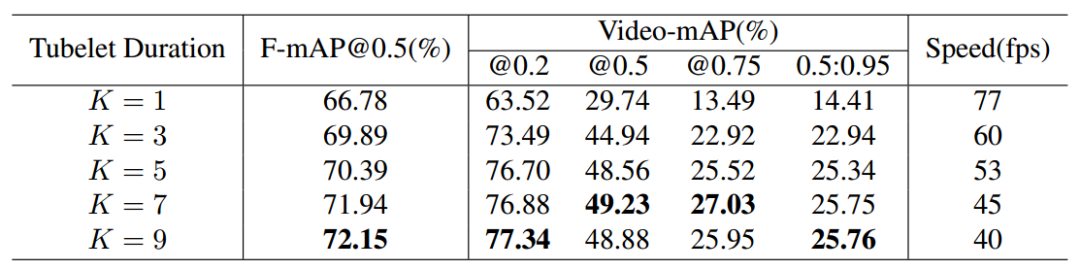
为了得到最佳的输入序列长度,研究人员比较了K=1-9的输出长度,通过权衡速度与精度决定使用k=7作为输入序列的长度,并可以实现25fps的预测速度。
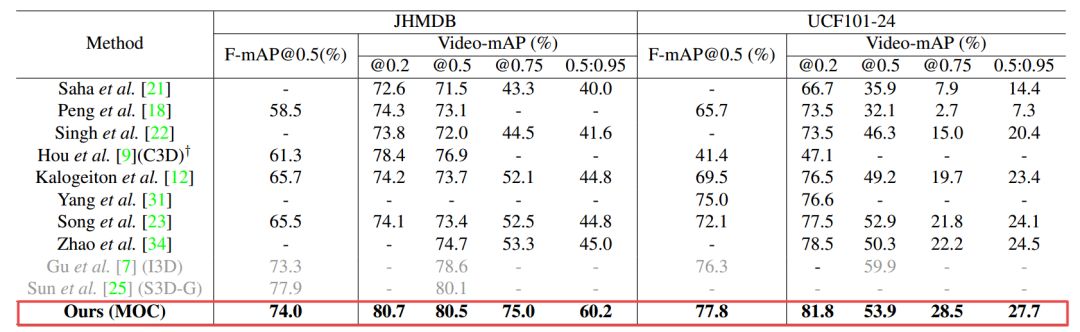
最终研究人员将本方法与目前最先进的检测方法在两个数据集上进行了比较,结果显示本方法在视频级和帧级的mAP都明显超越了先前的方法:
最后研究人员还对本方法的检测有效性进行了可视化,可以看到K=7时可更有效的检测出目标,漏检率更低;同时基于微行为管的检测使得分类误差也较小:

-
新冠肺炎诊疗方案再修改,确诊依据新增血清学检测,托珠单抗纳入治疗2020-03-05
-
佳能医疗:将启动研发快速新冠病毒检测系统2020-03-04
-
Wi-Fi运动检测能否成为电信运营商攻占智能家居市场的突破口?2020-03-03
-
检测小尺寸公差——塞规、气动量仪、电子测量该怎么选?2020-03-02
-
不是华为也不是BAT!这家AI企业可进行2000例/天的新冠核酸检测标2020-02-26
-
【生物医药日报】国家药监局已应急审批通过3家企业3个新型冠状病毒检测产品2020-02-25
-
美国研发半机械蝗虫 控制蝗虫大脑可检测爆炸物2020-02-20
-
AI热成像体温检测系统上线,一秒可检测4人2020-02-19
-
基于微流控技术的表面增强拉曼在细胞检测领域的应用2020-02-17
-
取指尖一滴血,15分钟出结果,Chembio Diagnostics 独有的DPP技术平台专注检测传染病2020-02-10
-
全力抗疫 阿里云宣布免费开放全球医疗、检测设备接入物联网平台能力2020-02-06
-
未一实验室新型冠状病毒检测服务准备就绪 与抗疫一线共克时艰2020-02-05
-
面对新型肺炎乙类传染,物联网设备如何检测人员健康?2020-01-23
-
科技抢速疫情丨27家企业宣布推出检测产品,病毒源于野生动物2020-01-23
-
应对疫情的中国速度:9天推出17款快速检测试剂盒,创新支付也在行动2020-01-22