摘译:认知体系研究综述|深兰科技
摘译:认知体系研究综述|深兰科技作为人工智能的一个重要分支,认知体系的研究和应用经过了近40年的发展,已取得了可见的成果。前两期内容对认知体系的概念、感知和注意力进行了介绍,本期将
作为人工智能的一个重要分支,认知体系的研究和应用经过了近40年的发展,已取得了可见的成果。前两期内容对认知体系的概念、感知和注意力进行了介绍,本期将继续分享关于行动选择和记忆的部分。
一般来说,行动选择决定在什么时间要做些什么,被分为“做什么”(即做什么决策)和“怎样做”(即动作如何控制)。例如,在MIDAS体系,行动选择包含了目标任务和执行这个选择的动作或行动。同样的,在MIDCA中,下一个动作通常是从一个被计划好的序列中选择出来的(如果这个序列存在的话)。因为在不同的认知体系中,行动选择的方法是不同的。在接下来的讨论中,行动选择机制可应用于决策和动作。
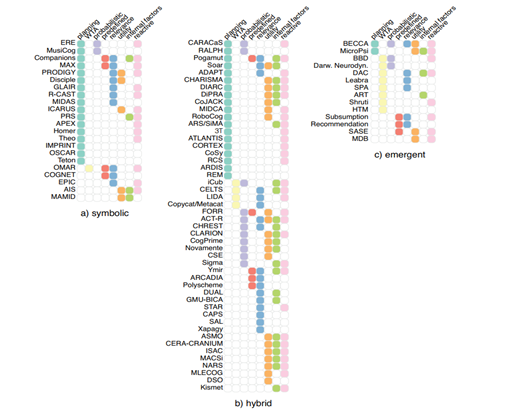
图1行动选择所涉及的机制
图1显示了所有被执行的行动选择机制,根据相关的体系类型(符号、混合、涌现)来组织。执行行动选择的主要两种方式:计划和动态。计划是事先制定一系列的步骤以达到一个确定的目标。在动态的行动选择中,一个最好的动作是从其他方案中被选择出来的,基于当时可获得的知识。对于这个类别,我们考虑选择的类别(赢者通吃、概率、预定义)和选择的标准(相关性、效用、感情)。默认选项一直是基于给定的标准做出的最好的动作(有最高激活水平的动作)。
最后,学习也可以影响行动选择,但会在第8节中讨论。注意,这些行动选择机制并不互相排斥并且大多数体系中有不止一种机制。尽管很少的体系会执行同样的行动选择机制,可行的组合空间通常会很大。
图1中可视化分为三列:符号、混合和涌现。注意,在这个图中,排序顺序强调具有相似动作的选择机制(或分别为记忆和学习方法)的体系结构簇。
1.1 计划与反应式动作
可以预见的是,计划型行动选择在符号范式体系中更加常见,但是也能在一些混合的甚至是涌现范式体系中被发现。尤其是在任务分解中,当目标被递归地分解成子目标,任务分解是计划动作的一种非常常见的形式。
其他被使用的计划动作的类型有:暂时性的、连续性的、层级性任务网络的、生成式的、基于搜索的、局部择优的等等。在我们的选择中,很少有体系仅仅只依赖于计划,例如OSCAR做逻辑推理和IMPRINT使用任务分解来模拟人类行动。除此之外,计划型行动选择经常利用加强动态的行动选择机制,来提升对变化的环境的适应性。
1.2 动态行动选择
动态行动选择能提供更多灵活性,并且能被用来模拟人类和动物。“赢者通吃”是神经网络中的一种选择策略(最强的输入被增强而其余的被抑制),它和它的变异体在各种新兴体系中很常见。同样的机制也被用来在所有体系中寻找最适合的动作,通常行动是多个并行过程的合作和竞争的结果。
行动选择的预定义序(方式)可能服务于不同目的。比如,在Subsumption体系中,机器人行动被附属行动等级所表示,高级行动优先于(包含)低级行动的输出。
在FORR中,做决策的部分根据递增顺序来从顾问中考虑选项,以达到与人类成员类似的学习。在YMIR中,优先级首先被给与到反应层中的过程中,然后是内容层,再是过程控制层。这里,目的是提供一个平滑的实时行动生成。每层有一个不同的认知反应时间上限,因此,反应式模块为用户提供自动的反馈(变化的脸部表情、自动发声),而审议性模块生成更复杂的行动。剩余的行动选择机制包含有限状态机制,被经常用来表示动作的顺序甚至来编译整个系统的行动,概率行动选择也常见。
行动选择标准
在选择下一个动作时,有多个标准要被考虑到:相关性、效用和感情(包括动机、情感状态、情绪、心情、积极性等)。
相关性反映出动作有多么契合现在的情况,这主要应用于有符号范式推理的系统和在应用前测试规则前/后的条件。动作的效用是测量为了达到现有目标的期望贡献。一些体系也会执行候选动作的“干运行(dry run)”,并观察他们的效果来决定他们的效用。效用也会考虑到过去动作的表现并在将来通过强化学习来促进行动的成长。其他机器学习技术也可以被用来把过去的成功行动和目标做关联。最后,内部因素并不直接决定下一个行动,但是会使选择存在偏差。
简单来说,我们会考虑关联到情绪、积极性和人类个性特征的短期、长期和终身因素。基于这些因素对于人类的决策和其他认知能力的影响,在认知体系中模拟情绪和情感是重要的,特别在人机交互、社交机器人和虚拟代理的领域。
3 首页 下一页 上一页 尾页-
世界首个逆转与阿尔茨海默病相关的记忆丧失的基因疗法2020-08-23
-
中兴通讯5G+工业互联网安全架构:“四体系一中心”2020-08-23
-
金九银十购车好时机,这三款高人气A级SUV该如何选择?2020-08-23
-
高端TWS耳机市场争夺战,vivo选择高通QCC5126蓝牙SoC2020-05-21
-
高科技企业品牌突围为什么要选择数字营销?2020-05-21
-
智配之道——物流末端体系创新助力智能社区建设2020-05-20
-
如何选择适合实验的微孔板?2020-05-14
-
原厂的更香 雷神记忆魔人DDR4-3000内存测试2020-05-14
-
人工智能“匠心独运” 修复老片找回褪色的记忆2020-05-12
-
老板牌抽油烟机价格多少?除了老板牌抽油烟机还有更好的选择2020-05-11
-
科普 | M2M与IoT有何区别,该如何选择?2020-05-09
-
傅利叶智能完成 B+ 轮融资,用于技术研发以及康复生态体系建立2020-05-06
-
吉利公开招聘火箭总师;三部门印发国家车联网产业标准体系建设指南2020-04-27
-
三部门:2025年系统形成支撑车联网环境下的车辆智能管理标准体系2020-04-26
-
三部门:到2025年系统形成支撑车联网环境下的车辆智能管理标准体系2020-04-26