推理部分
下图是整个Encoder-Decode的结构。通过上面的理解,我觉得这个图非常清晰。
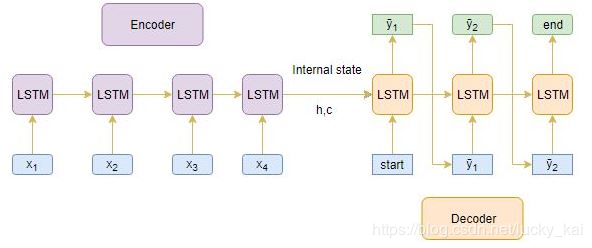
Encoder整个输入序列,并且用Encoder最后一个状态结果来初始化Decoder。
将[start]作为输入传递给解码器Decoder。
使用通过Encoder初始化过的Decoder运行一个time stpe。
输出将是下一个单词的概率,将选择概率最大的单词。
这个预测的单词将会在下一时间Step中作为输入。并且通过当前状态更新内部参数。
重复步骤3-5,直到生成[end]或达到目标序列的最大长度。
Encoder-Decoder结构的局限性
Encoder将整个输入序列转为固定的长度,但是当序列很长的时候,Encoder将会很难记住整个序列的内容,无法将所有必要信息准确的编码到固定长度。但是,我们需要关注序列中所有的内容么,不需要。
注意力机制
为了解决长句子的问题,注意力机制出现在人们的视野。注意力机制为对结果重要的部分添加高的权重,以保留主要信息。举个例子:
需要编码的序列[x1,x2,x3,x4,x5,x6,x7] Source sequence: “Which sport do you like the most?
需要解码的序列[y1,y2,y3] Target sequence: I love cricket. 我们可以判断,y1[I]与x4[you]有关,而y2[love]则与x5[like]有关。所以,相比记住序列中的所有单词,不如增加对目标序列重要部分的权重,忽视低权重的部分。
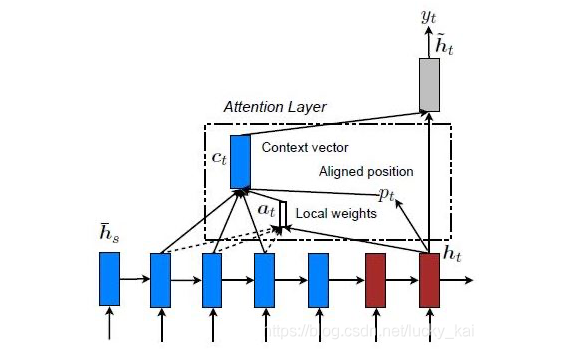
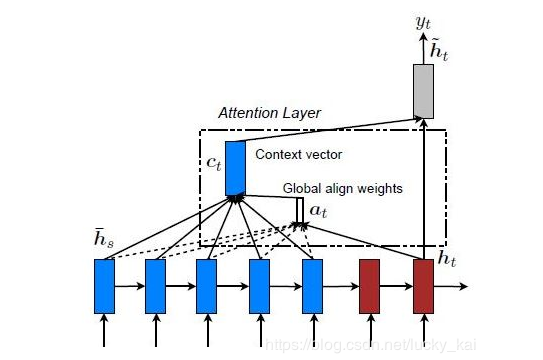
Global Attention and Local Attention
全局注意力机制 编码器的隐藏层中,所有部分都参与attention的计算上下文。
局部注意力机制 编码器的隐藏层中,仅有部分参与attention的计算上下文。
本文最终采用全局注意力机制。(只是添加了注意力机制,编码的固定长度依然需要固定。所以实战中需要通过数据确定一个合适的长度数值。短了无法表达文本内容,长了会造成计算资源浪费。)
实战
我们的目标是为亚马逊美食评论生成文本摘要。(这里我只提取了我觉得有用的部分)
数据表述
这些评论通常很长而且具有可描述性。数据集下载:kaggleData。 数据涵盖了超过10年的时间,包括截至2012年10月的所有?500,000条评论。这些评论包括产品,用户信息,评级,纯文本评论和摘要。它还包括来自所有其他亚马逊类别的评论。
数据处理
由于评论文本和摘要中涉及的预处理步骤略有不同,因此我们需要定义两个不同的函数来预处理评论和摘要。
评论文本处理
将所有字母小写;
移除HTML标签;
Contraction mapping;
移除(‘s);
删除括号内的内容(觉得括号里面的内容解释说明不重要);
消除标点符号和特殊字符;
删除停用词;
删除低频词;
摘要文本处理
为摘要文本添加[start]和[end]。
数据分布
通过数据统计,可以看到摘要与文本数据的长度分布。通过数据可视化,我们可以将评论文本的长度限定在80,而摘要的长度限定在10。
3


