百度提出的持续学习语义理解框架RNIE基本原理简析
百度提出的持续学习语义理解框架RNIE基本原理简析本文以通俗易懂的语言介绍了百度提出的 持续学习语义理解框架 ERNIE 的基本原理,和利用 ERNIE 来解决下游 NLP 任务的
本文以通俗易懂的语言介绍了百度提出的 持续学习语义理解框架 ERNIE 的基本原理,和利用 ERNIE 来解决下游 NLP 任务的过程。
一、简介
人工智能这个古老而又年轻的学科,正在经历一场由深度学习引领的革命。深度学习最早在图像和语音领域取得成功,人们发现在解决这两个领域的问题时,各类基于神经网络的方法大大超越了其它传统方法的效果。随后这样的变革也发生在了自然语言处理 (NLP) 领域。时至今日,人们在处理 NLP 任务时,例如词法分析、语言模型、机器翻译等,通常会选择构建各种神经网络来解决,这已形成了一种范式。不过,不同任务所适用的神经网络可能千差万别,人们要把相当大的精力放在神经网络结构的设计或者选择上来,这无疑增加了深度学习的使用成本。
近年来,语义表示(language representation)技术的发展,使得 “预训练-微调” 作为解决NLP任务的一种新的范式开始出现。一个通用的表示能力强的模型被选择为语义表示模型,在预训练阶段,用大量的语料和特定的任务训练该模型,使其编码海量的语义知识;在微调阶段,该模型会被加上不同的简单输出层用以解决下游的 NLP 任务。
早期较为著名的语义表示模型包括ELMo 和 GPT ,分别基于双层双向LSTM和Transformer Decoder框架,而真正让语义表示技术大放异彩的是BERT (Bidirectional Encoder Representations from Transformers) 的提出。BERT以Transformer Encoder为骨架,以屏蔽语言模型 (Masked LM) 和下一句预测(Next Sentence Prediction)这两个无监督预测任务作为预训练任务,用英文Wikipedia和Book Corpus的混合语料进行训练得到预训练模型。结合简单的输出层,BERT提出伊始就在11个下游NLP任务上取得了 SOTA(State of the Art)结果,即效果最佳,其中包括了自然语言理解任务GLUE和阅读理解SQuAD。
可以看到,用语义表示模型解决特定的NLP任务是个相对简单的过程。因此,语义表示模型的预训练阶段就变得十分重要,具体来说,模型结构的选取、训练数据以及训练方法等要素都会直接影响下游任务的效果。当前的很多学术工作就是围绕预训练阶段而展开的,在BERT之后各种语义表示模型不断地被提了出来。
ERNIE(Enhanced Representation through kNowledge IntEgration)是百度提出的语义表示模型,同样基于Transformer Encoder。相较于BERT,其预训练过程利用了更丰富的语义知识和更多的语义任务,在多个NLP任务上取得了比BERT等模型更好的效果。
项目开源地址:https://github.com/PaddlePaddle/ERNIE
该项目包含了对预训练,以及常见下游 NLP 任务的支持,如分类、匹配、序列标注和阅读理解等。
二、基本原理Transformer Encoder
ERNIE 采用了 Transformer Encoder 作为其语义表示的骨架。Transformer 是由论文Attention is All You Need 首先提出的机器翻译模型,在效果上比传统的 RNN 机器翻译模型更加优秀。
Transformer 的简要结构如图1所示,基于 Encoder-Decoder 框架, 其主要结构由 Attention(注意力) 机制构成:
Encoder 由全同的多层堆叠而成,每一层又包含了两个子层:一个Self-Attention层和一个前馈神经网络。Self-Attention 层主要用来输入语料之间各个词之间的关系(例如搭配关系),其外在体现为词汇间的权重,此外还可以帮助模型学到句法、语法之类的依赖关系的能力。
Decoder 也由全同的多层堆叠而成,每一层同样包含了两个子层。在 Encoder 和 Decoder 之间还有一个Encoder-Decoder Attention层。Encoder-Decoder Attention层的输入来自于两部分,一部分是 Encoder 的输出,它可以帮助解码器关注输入序列哪些位置值得关注。另一部分是 Decoder 已经解码出来的结果再次经过Decoder的Self-Attention层处理后的输出,它可以帮助解码器在解码时把已翻译的内容中值得关注的部分考虑进来。例如:将“read a book”翻译成中文,我们把“book”之所以翻译成了“书”而没有翻译成“预定”就是因为前面Read这个读的动作。
在解码过程中 Decoder 每一个时间步都会输出一个实数向量,经过一个简单的全连接层后会映射到一个词典大小、被称作对数几率(logits)的向量,再经过 softmax 归一化之后得到当前时间步各个词出现的概率分布。
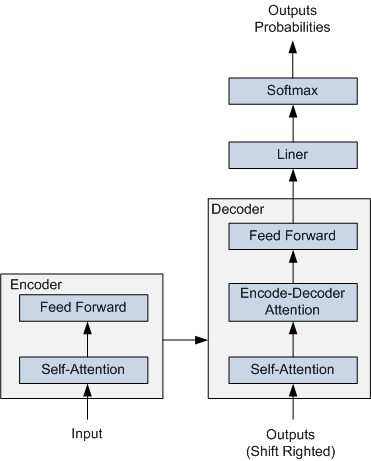
图 1 Transformer 的简要结构图
Transformer 在机器翻译任务上面证明了其超过 LSTM/GRU 的卓越表示能力。从 RNN 到 Transformer,模型的表示能力在不断的增强,语义表示模型的骨架也经历了这样的一个演变过程。
如图2所示,该图为BERT、GPT 与 ELMo的结构示意图,可以看到 ELMo 使用的就是 LSTM 结构,接着 GPT 使用了 Transformer Decoder。进一步 BERT 采用了 Transformer Encoder,从理论上讲其相对于 Decoder 有着更强的语义表示能力,因为Encoder接受双向输入,可同时编码一个词的上下文信息。最后在NLP任务的实际应用中也证明了Encoder的有效性,因此ERNIE也采用了Transformer Encoder架构。
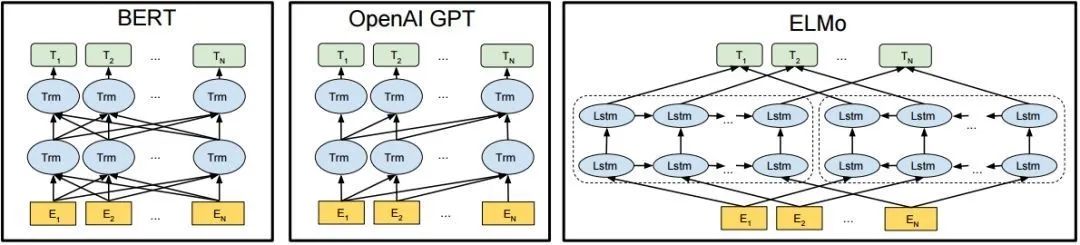
图2 BERT、GPT 与 ELMo
首页 下一页 上一页 尾页-
干货知识:3D打印机操作小技巧,告别惨不忍睹的模型2020-12-16
-
首个AI训练数据解决方案发布,加速智能驾驶产业成熟2020-12-07
-
法国初创公司CTIBiotech两种生物打印全皮肤模型2020-12-01
-
《中国移动物模型标准白皮书》重磅发布 为物联网设备互动及业务快速复制奠基2020-11-30
-
训练AI的方式 从根本上有缺陷?2020-11-30
-
如何提高光固化3d打印模型的精度?2020-11-24
-
语义分割与实例分割的区别2020-11-21
-
在 AI 机器视觉时代, 人脑训练还有意义吗?2020-11-13
-
曼纽科康复训练机器人何以独步天下?2020-10-31
-
不懂算法和模型?用友精智工业大脑教你轻松驾驭工业智能2020-10-23
-
打通教学与实践,海克斯康智教数控五轴模拟训练机让机床进入教室2020-10-20
-
模型下载:NASA公开毅力号火星车、机智号无人机3D可打印数据2020-08-23
-
创想三维:如何提高3D打印模型的精度?2020-08-23
-
教你如何提高光固化3D打印模型的精度2020-08-23
-
重磅!科学家培育出新冠病毒转基因小鼠模型2020-08-23