百度大脑EdgeBoard计算卡评测
百度大脑EdgeBoard计算卡评测ResNet模型前言我们自己训练一个ResNet模型,并在以下三个环境中进行性能的对比。AIStudio CPU: 2 Cores 8GB Me
ResNet模型
前言
我们自己训练一个ResNet模型,并在以下三个环境中进行性能的对比。
AIStudio CPU: 2 Cores 8GB Memory
AIStudio GPU: V100 16GB VMem
Edgeboard
训练模型
模型使用AIStudio 进行训练,RESNET、MOBILE训练和预测代码有兴趣的同学请手动移步到百度AI社区相关帖子里查看详细内容。百度AI社区——EdgeBoard板块。
测试结果
我们执行预测,忽略掉预处理的速度,仅仅计算模型前向传播的时间。
对于AIstudio平台,我们计算以下代码的运行时间

对于Edgeboard上面的PaddleMobile,我们计算以下代码的运行时间

以下为两个模型的评测数据
ResNet
Edgeboard:

CPU:

GPU:

Mobile_Net
Edgeboard:

GPU:
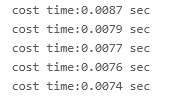
CPU:

总结:
下表为两个模型预测速度的对比,从中来看,其速度相对于V100的GPU甚至还有一定的优势,让人难以相信。个人的分析是由于以下几个原因
Paddle-mobile较为启动预测,与AIstudio的完整版Paddlepaddle相比有启动效率上的优势,AIstudio启动预测可能较慢。
整个预测模型batch size相当于1,发挥不出GPU的优势。
部署预算按三年算的话,GPU V100价格大概是10万,CPU 1万, EdgeBoard 5千,性价比还是蛮高的。如果大家对Edgeboard感兴趣的话,可自行到百度AI市场购买体验,我在这里不做过多赘述。

我在进行模型预测的时候,使用钳表对功率进行了大概的估计(条件有限),钳表的读数在0.6A-8A之间变化。结合使用的12V适配器,我大概估计Edgeboard的功耗为8W.
以8W的功耗,在单张图片的预测速度上面领先了几十倍功耗的GPU与CPU。Edgeboard的表现还是令我比较惊喜。本来想继续移植一个前段时间的大尺度的分割网络Unet进行尝试,想继续试试他最大可以跑的模型大小,但似乎Edgeboard目前还不支持分割,存在了一定遗憾。
另外我在进行调试的时候,发现过有几个发布版本的固件不是很稳定,有些op有些问题。还发现了Edgeboard在我的两台笔记本电脑上网络不是很稳定,经常出现相互无法ping通的情况,更换PC后正常,暂时还没发现为什么。
Edgeboard是我第一款接触的嵌入式神经网络加速设备。Paddle-mobile也是我接触的第一个移动端神经网络框架,也是我接触的第一个基于FPGA实现的加速框架。从我了解这个框架到现在仅仅不到半年的时间,已经发布了多个模型转换工具,降低了开发难度,并且支持EasyDL这种方式。虽然目前仍然有一些不成熟的坑需要填,不过相信在软件的迭代下面,它能成为一个很好的嵌入式原型设计平台。
Mobile-SSD模型
这次我们自己训练一个Mobilenet-SSD模型,增加了不同输入维度的情况下,模型运行效率的对比
AIStudio CPU: 2 Cores 8GB Memory
AIStudio GPU: V100 16GB VMem
Edgeboard
训练模型
模型使用AIStudio提供的官方工程进行训练,Mobilenet-SSD训练和预测代码有兴趣的同学请手动移步到百度AI社区相关帖子里查看详细内容。百度AI社区——EdgeBoard板块。
运行预测
我们执行预测,忽略掉预处理的速度,仅仅计算模型前向传播的时间。
对于AIstudio平台,我们计算以下代码的运行时间

对于Edgeboard上面的PaddleMobile,我们计算以下代码的运行时间

以下图片为预测结果,由于时间有限,没有很细致去训练模型,仅仅对比了模型运行的速度。

下表为模型在不同维度下的预测速度的对比,从中来看,其速度相对于V100的GPU基本处于同一个数量级,远远领先与CPU

在之前的文章里我们提到,本来想继续移植一个前段时间的大尺度的分割网络Unet进行尝试,想继续试试他最大可以跑的模型大小,但似乎Edgeboard目前还不支持分割,所以我们更换了目标检测网络进行尝试。在mobilenet-SSD这个模型上,Edgeboard最大可以跑到700*700的输入维度,并且能保持在16fps之上(不包含输入图像的语出过程),基本上具有实时性。
之前我提到的,在我的两台笔记本电脑上网络不是很稳定,经常出现相互无法ping通的情况,目前经过试验之后,发现问题为板子的网卡在与不支持千兆的网卡进行通信时候,不能正确的协商,仍然使用千兆模式,使用以下命令固定为百兆即可正常连接
ethtool -s eth0 speed 100 duplex full
Edgeboard是我第一款接触的嵌入式神经网络加速设备。Paddle-mobile也是我接触的第一个移动端神经网络框架,也是我接触的第一个基于FPGA实现的加速框架。从我了解这个框架到现在仅仅不到半年的时间,已经发布了多个模型转换工具,降低了开发难度,并且支持EasyDL这种方式。虽然目前仍然有一些不成熟的坑需要填,不过相信在软件的迭代下面,它能成为一个很好的嵌入式原型设计平台。
无相关信息