TransRepair:自动测试及修复神经网络翻译模型的不一致性问题
TransRepair:自动测试及修复神经网络翻译模型的不一致性问题机器翻译是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,机器翻译又具有重要的实用

机器翻译是计算语言学的一个分支,是人工智能的终极目标之一,具有重要的科学研究价值。同时,机器翻译又具有重要的实用价值。随着经济全球化及互联网的飞速发展,机器翻译技术在促进政治、经济、文化交流等方面起到越来越重要的作用。
机器翻译虽已广泛应用于各个领域,但现有神经网络测试工作均未在自然语言处理的模型上进行过测试。然而,研究发现在这些翻译模型中存在不一致性问题。发表于 ICSE 2020 的论文《Automatic Testing and Improvement of Machine Translation》率先对机器翻译进行测试,并提出了一种用于检测及修复神经网络翻译器中所存在的不一致性问题的方法——TransRepair。
TransRepair 结合了变异测试及蜕变测试两种方法以检测不一致性问题。对于所检测的问题,提出了一种基于概率的后处理方法以对该问题进行修复。本期 AI Time PHD 直播间,我们很荣幸地邀请到论文的一作,北京大学孙泽宇博士为大家分享他们的研究成果!

孙泽宇,北京大学信息科学技术学院 2019 级博士生,导师为张路教授,指导老师为熊英飞研究员。主要研究方向为程序自动生成和软件测试,已在相关领域的国际顶级会议如ICSE, AAAI, IJCAI, FSE等发表多篇论文。
研究动机:机器翻译的不一致性
随着机器学习的发展,多用途的自然语言翻译系统相继问世,许多系统能够实时有效地在数千种语言之间进行翻译。然而事实上,大多翻译系统并不完美,存在大量翻译上的错误。
研究发现,人为的误译可能造成非常严重的后果,成为改变历史的导火索。例如,19 世纪末著名的《乌查里条约》误译事件。由于意大利对条约第17条错误的翻译,最终导致了意大利和埃塞俄比亚两国爆发战争。
同样,机器翻译的误译也会造成困惑及误解。例如,将传统小吃“四喜烤夫”翻译成“roasted husband”,将“小心滑倒”译为“slip and fall down carefully”等。更为严重地,出现不公平性现象,对特定的用户群体造成伤害。图1显示了几个语言对(英语→中文)的谷歌翻译结果,当主语是“men”或“male students”,将“good”翻译成“很好的 (very good)”,然而当主语是“women”或“female students”时,则将“good”翻译成“很多 (a lot)”,这种不一致性不仅会让用户感到困惑,而且显然对计算机科学领域的女性研究人员也不公平。与进行“very good”研究相比,进行“a lot”研究明显是一种更具贬义的解释。为了避免这种翻译错误,需要能够自动识别和纠正不一致性的技术。

图1 翻译不一致产生的公平问题的示例
方法:如何解决不一致性问题
针对机器翻译中的不一致性问题,传统机器学习系统的修复方法一般是使用数据增强或算法优化,提高机器学习的整体性能,不针对单个错误进行特定修复;同时还需要数据收集、标注和模型的再训练,通常来说成本很高。
另外,传统修复软件错误的方法是白盒,当识别出需要修改的源代码后才能进行修复,但这种方法不能用于修复源代码不可用的软件,比如第三方代码。

图2 不一致性问题的传统修复方法
为改进传统修复方法存在的缺陷,孙泽宇等提出了一种用于检测及修复神经网络翻译器中所存在的不一致性问题的组合方法——TransRepair,结合变异测试及蜕变测试的方法对不一致性问题进行测试,并通过黑盒和灰盒两种方式自动修复在测试阶段发现的翻译错误。

图3 TransRepair方法
TransRepair 测试及修复概述

图4 TransRepair测试及修复不一致性问题概述
图4为 TransRepair 测试及修复的过程概述,主要有以下三个步骤:
1) 自动测试输入生成生成用于一致性测试的句子,对每个句子使用上下文相似的单词进行替换,生成的候选变异句使用语法检查进行筛选,通过筛选的变异句将作为被测机器翻译的输入。
2) 自动测试oracle生成根据翻译输入和输出之间的蜕变关系,生成oracle以识别不一致的翻译,思想是,翻译原句与其上下文相似变异句的输出应具有一定程度的一致性。使用相似度指标衡量翻译输出和oracle的一致性程度。
3)自动不一致性修复自动修复具有不一致性的翻译,有黑盒和灰盒两种方法,根据变异中最优的翻译对原译文进行转换。考虑两种最优翻译的选择方法,一种是预测概率法,另一种是交叉引用法。
一、测试
测试第一步是构建上下文相似语料库。进行上下文相似的单词替换的关键步骤是,找到一个可以被其他相似单词替换、且不影响句子结构的单词,替换生成的新句应与原句的翻译一致,单词之间的相似度通过词向量进行衡量。
为了构建一个可靠的上下文相似语料库,采用 GloVe、SpaCy 两种词向量模型,并使用其训练结果的交集。当两个单词在两个模型中的相似度都超过 0.9 时,则认为它们是上下文相似的,将这对单词放入上下文相似语料库中,得到变异算子。以图 5 的句子为例,通过计算词向量相似度,衡量句中“Male”和“Female”能否进行替换?在设定的标准下,答案是可替换的。

图5 上下文相似语料库构建
构建好上下文相似语料库后,下一步进行翻译输入变异。首先是单词替换,对于原句中的每个单词,在语料库中搜索是否存在匹配单词,如果找到了一个匹配的词,替换并生成变异句。同一单词在不同语境下意思或许有所不同,但上述替换只考虑了整体语境,忽视了具体情况下的差异,因此替换的单词可能不适合新句子的上下文,导致生成的变异句无法解析。
为解决此类解析失败问题,提出通过附加约束来检测变异句的合理性,基于 Stanford Parser 进行结构过滤。分析得到原句和变异句的语法树,假设二者结构相同,则认为对原句的变异在结构上是合理的,反之不合理,从候选中删除。
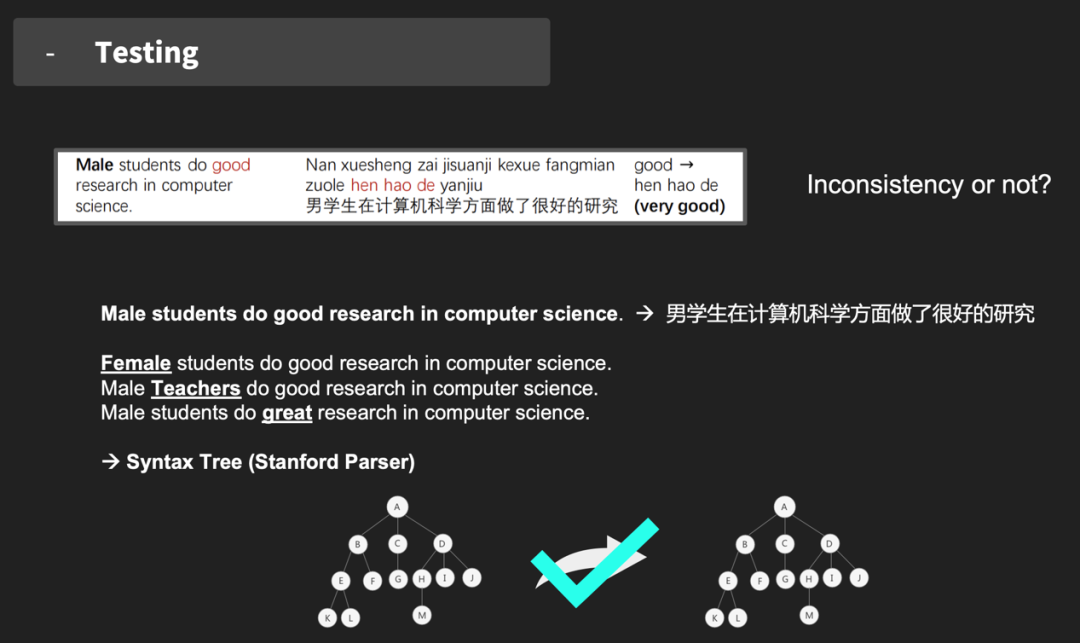
图6 翻译输入变异
通过对原句和变异句的翻译结果进行比较,测试翻译是否具有一致性。具体做法是对原句和变异句的译文进行切片,删除部分得到不同子序列并分别计算它们的相似度。相似度计算主要采用 Tf-idf, BLEU, LCS, ED 等几种常用方法,使用最高相似度作为最终一致性评分的结果。当最终相似度小于设定的阈值时,认定为翻译不一致。

图7 翻译不一致性测试
二、黑盒和灰盒修复
发现问题就要解决问题,下一步工作是对识别出的不一致性问题进行修复。同样以之前的句子为例,在将“Male”改为“Female”之后,对“good”的翻译从“很好”变为了“很多”,那么究竟哪个翻译是正确的还是都不正确?首先任取一句话作为原句,然后通过上述测试同样的方法对句子进行变异,生成变异句并进行翻译。使用预测概率(Predictive probability)或交叉引用(cross reference)对原句及变异句的译文进行排序,排序高者为候选目标翻译,再利用词对齐(Word Alignment)寻找单词之间的映射关系,生成最终修复后的翻译结果。
其中,利用预测概率意在选择出现概率最高的译文成为修复依据,是一种灰盒修复方法,既不需要训练数据,也不需要训练算法的源代码,只需要机器翻译提供的预测概率。而交叉引用是计算译文之间的相似度,两两比较后找到与其他句子相似度最高的译文,是一种黑盒修复方法,只需要翻译器的输出。

图8 不一致性问题修复

图9 词对齐后的翻译结果
TransRepair的模型评估
TransRepair能够自动检测和修复机器翻译中的不一致性问题,那么模型性能究竟如何,还需要进行评估。对TransRepair的评估主要围绕以下三个问题:
问题一
TransRepair测试输入的准确度?
问题二
TransRepair发现bug的能力?
问题三
TransRepair修复bug的能力?
评估实验主要通过谷歌翻译和 Transformer 模型两个机器翻译器进行,测试数据集为News Commentary。对于每个测试句,生成变异句并检查它们是否通过了结构过滤。2001 个测试句一共生成 21960 个变异句,过滤掉 17268 句保留 4692 句作为测试输入,随机抽取 400 句手动评估它们是否能够检测翻译不一致性,查看变异句的替换词是否会导致语法错误、变异体的翻译是否与原句一致。这一验证步骤发现了三个无效的变异句,其余的 397 句符合有效性标准,准确率为 99%,说明 Transformer 有很高的概率能够产生有效的测试句。

图10 测试输入准确度
使用谷歌翻译和 Transformer 对 4692 个变异句进行翻译,将它们与原始句的翻译进行比较,计算每个变异句的四种一致性得分,图 11 右边为一致性得分直方图,四种度量都发现了大量得分低于 1.0 的翻译,表明翻译存在不一致性。图 11 左边为四种度量不同阈值下的不一致翻译个数,可以看到即使在一致性阈值较宽松时,bug 依然存在。

图11 一致性指标值
手动检查变异句和原句的翻译,不一致错误的条件为:1)有不同的含义;2) 有不同的情感色彩;3)专有名词使用了不同的字符表示。最后结果如图12,可以看出Transformer 在发现 bug 问题上能够有很好地表现。

图12 Transformer发现bug能力的实验结果
对所有不一致的翻译进行修复,检验 Transformer 对 bug 的修复能力,修复结果对比见图 13。黑盒平均减少了谷歌翻译 28% 的 bug,灰盒修复了 Transformer 30% 的 bug、黑盒修复了 19% 到 20% 的 bug,表明灰盒和黑盒方法是修复不一致缺陷的有效方法。
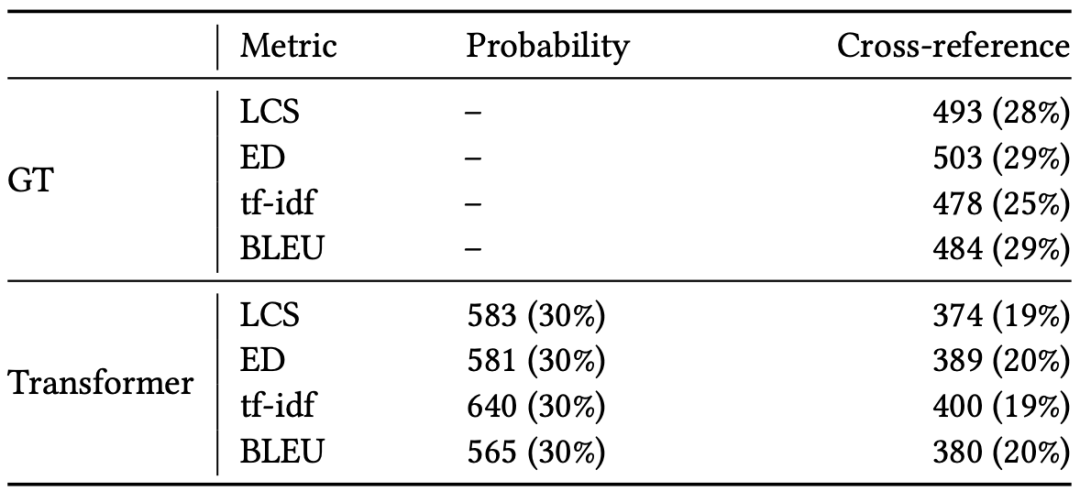
图13 Transformer不一致性修复结果
手动比较修复前后的翻译一致性&修复前后翻译的可接受性(原句和变异句),考虑充分性和流利性,手动出“Improved”、“Unchanged”或“Decreased”标签,结果见图 14。表明 TransRepair 在提高翻译一致性方面有很好的效果,平均 87% 的谷歌翻译和 Transformer 翻译的一致性提高了。

图14 Transformer修复bug能力的实验结果
扩展分析和讨论
之前的工作采用了数据增强的方法提高机器学习模型的鲁棒性,对于源代码已知的翻译器,训练数据增强是增加翻译一致性的方案之一,因此设计实验研究添加更多的训练数据是否会产生更好的翻译一致性。使用 10%, 20%, ..., 90% 的原始训练数据分别训练 Transformer,结果见图 15,当比例在 0.7 到 1.0 之间时,没有观察到 bug 下降的趋势,这说明增加训练数据对改善翻译不一致性的效果有限。
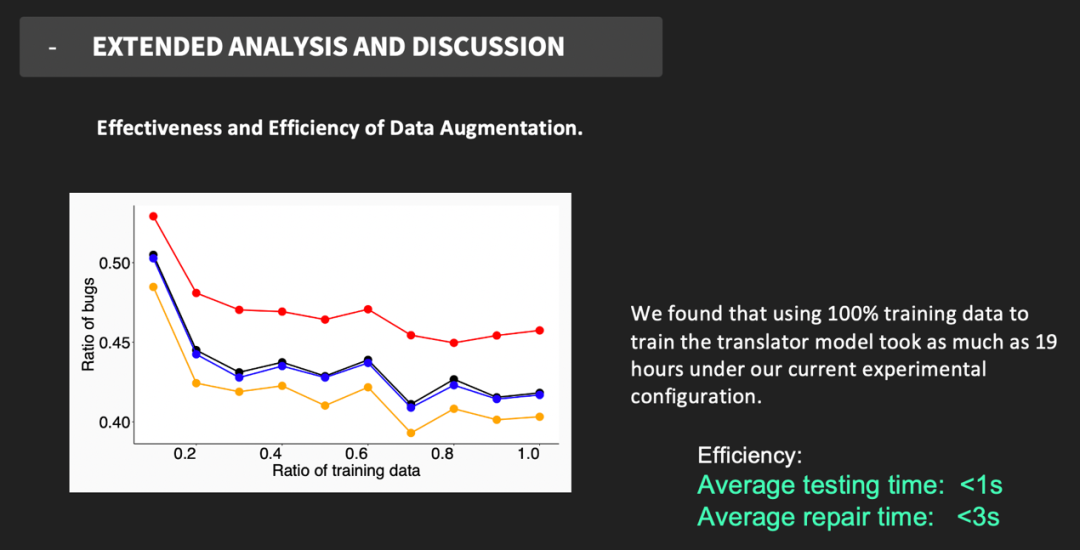
图15 数据增强实验结果
在不一致检测和修复过程中都会产生变异句,为了研究变异句的数量如何影响检测和修复性能,比较不同设置下不一致的 bug 数和修复的 bug 数,灰盒修复结果如图 16 所示。可以看到在检测时,使用更多的变异句有助于发现和修复更多不一致的问题。
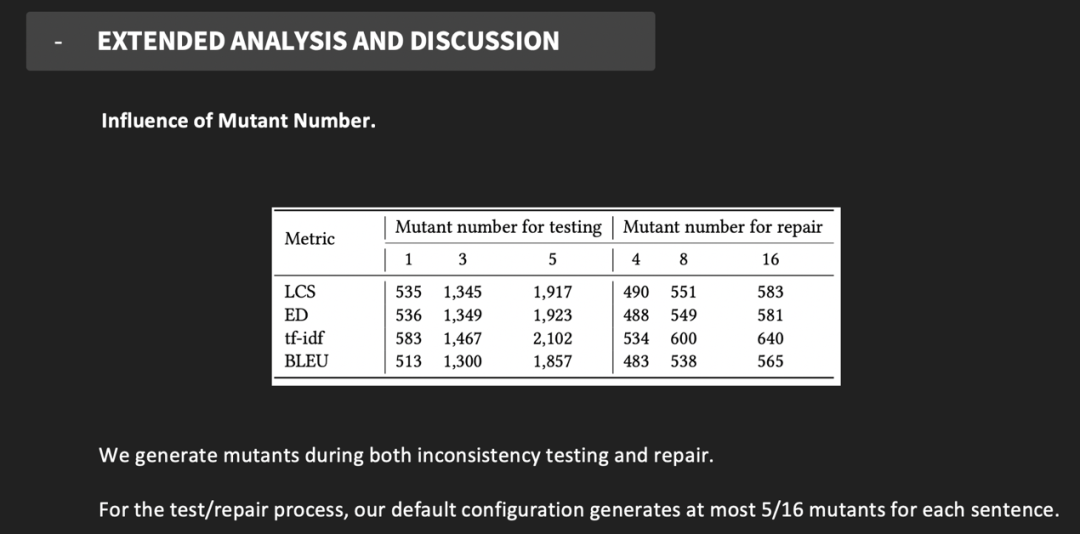
图16 不同变异句数量比较结果
TransRepair 可以应用到端到端模型上,给定输入和翻译器,将自动测试和修复翻译输出,并向用户提供新的翻译输出。图 17 是 TransRepair 的几个具体使用示例。

图17 TransRepair使用示例
总结来说,TransRepair 通过黑盒和灰盒方法,在自动测试和修复机器翻译不一致性问题上具有很好的表现。不需要源代码,不需要训练数据,能够修复特定错误,不仅成本较低,还具有高效、实时、灵活等优点。



点击阅读原文,下载本次报告!
喜欢本篇内容,请分享、点赞、在看
上一篇:各种装配夹具,来看看适合你用的
-
AI修复百年前北京城爆火!老北京原来长这样2020-05-14
-
人工智能“匠心独运” 修复老片找回褪色的记忆2020-05-12
-
跑赢业内大盘,日活逆势大涨的百度翻译有什么魔力?2020-05-11
-
QQ邮箱致歉回应崩溃:系后台服务波动,已修复2020-05-07
-
实时翻译是如何实现的?2020-04-26
-
苹果回应邮件漏洞:立刻修复漏洞2020-04-24
-
将修复!苹果回应邮件漏洞:黑客可任意入侵、篡改数据2020-04-24
-
骁龙AI与有道携手 利用实时翻译架起沟通的桥梁2020-04-23
-
浙江大学发现新冠病毒至少有30种变异 欧洲的变异比美国更致命2020-04-22
-
中科院计算所副研究员冯洋:神经机器翻译的训练改进和解码提速2020-04-07
-
HPE新固件修复40000小时SSD掉盘问题:锅在OEM厂商2020-03-26
-
华诺生物:研发可注射、高抗压性自修复水凝胶材料,满足创伤修复领域医械耗材需求2020-03-22
-
获得4轮融资,BioStable的三款瓣膜修复置换技术产品为何受青睐?2020-03-21
-
伊朗翻译诊疗方案:医疗机器人再次出征2020-03-03
-
阿里巴巴达摩院用AI修复经典老剧 实现4K HDR2020-01-21