配置介绍:
config.setMaxDepthOfCrawling(int maxDepthOfCrawling):抓取深度限制,默认抓取深度不受限制(设定值为-1也不受限制)。如种子页面为A,A链接到B,B链接到C,C链接到D。种子页面A的深度为0,B的深度为1,以此类推。如果设定值为2,就不会抓取到D链接的内容。
config.setPolitenessDelay(int politenessDelay):每次请求前等待毫秒数,默认不等待。可以防止抓取请求过快而被服务器端认为是非法请求而终止访问的情况。
可以通过如下代码设定代理设置:
crawlConfig.setProxyHost("proxyserver.example.com");
crawlConfig.setProxyPort(8080);
如果代理需要认证:
crawlConfig.setProxyUsername(username);
crawlConfig.getProxyPassword(password);
解析器
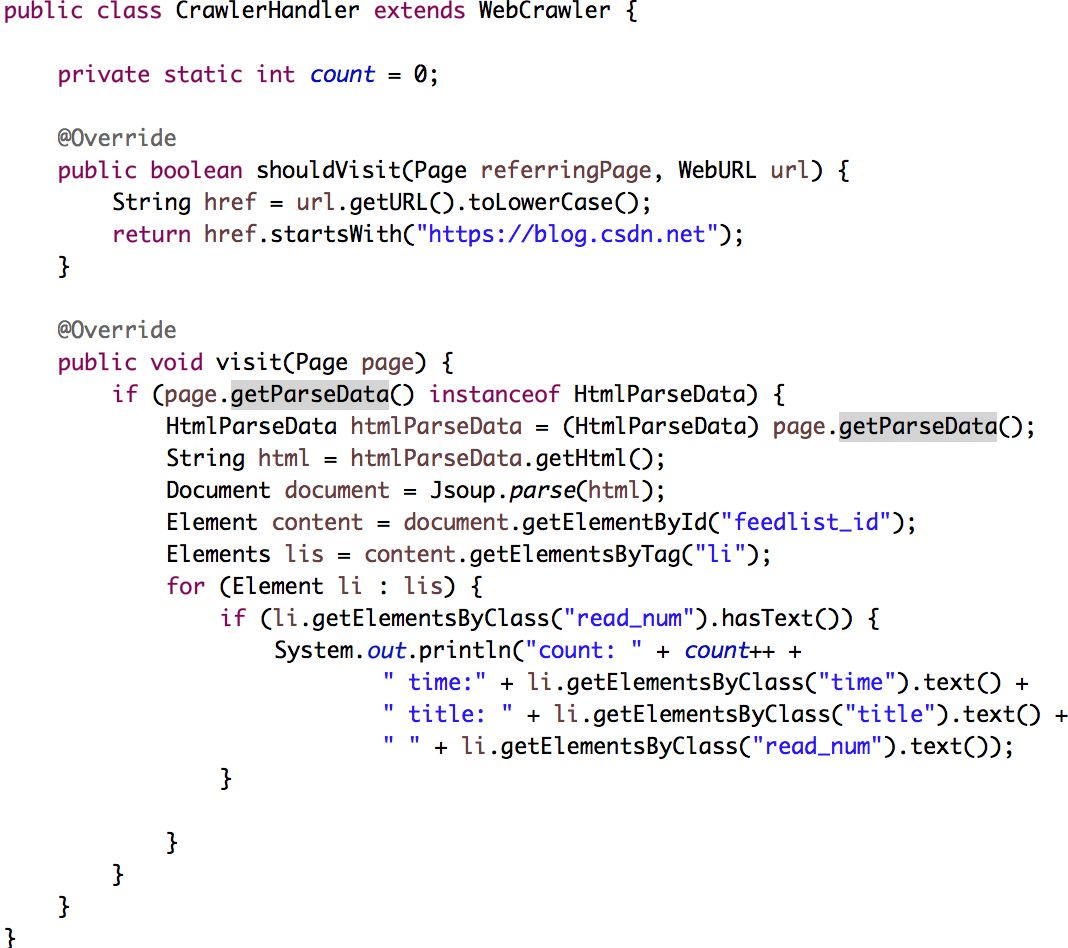
代码解释:
shouldVisit():用来实现满足抓取数据的条件,如满足抓取条件则返回true,返回false代表不满足条件则放弃本次抓取。
visit(): 抓取返回的响应结果,此示例中通过Jsoup来解析响应内容。Jsoup的代码解析语法遵循Javascript规范要求,对熟悉Javascript的开发者使用起来比较方便易懂。
标签定位:HTML标签定位可以通过浏览器控制台的方式进行查看。
资源库:
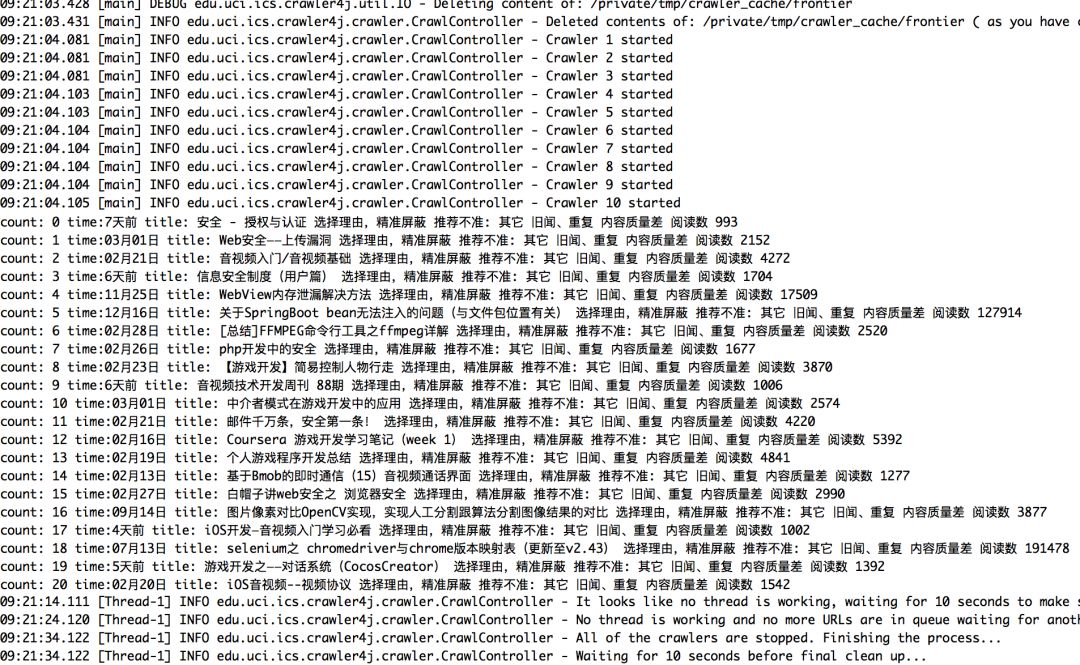
本示例中通过Java标准输出流来替代资源库的实现部分,未单独实现资源库的代码。从输出结果可以看出项目设定10个线程同时抓取满足条件的第一级深度的博客文章共计21篇。
规避反爬虫技术
在实际项目抓取的过程中应该满足君子协议即不违背robots.txt定义的抓取协议。同时爬虫项目的开发中可能会遇被抓取的WEB网站对访问频繁程度的限制,异步Ajax动态渲染数据等。可以参考如下方法解决:
通过设定动态IP代理的方式,每抓取几次之后动态更换IP地址,让服务器端判断每次IP来源不同;
通过设定抓取前休眠时间来降低抓取频度;
分析动态Ajax请求,结合Jsoup进行单独的URL请求,获取异步请求数据响应内容;
通过Selenium等相关自动化测试工具,模拟真实的浏览器请求获取Ajax异步请求渲染之后的数据;
通过设定Header中的值,来规避相关请求参数的限制。



